

当遇到典型的产品或工程组织时,团队成员经常会怀疑他们所做的事情是否产生了影响,或者他们在许多不同的设计中所做的选择,是否是最好的。
当这些团队想要以数据为基础来影响决策方向时,AB测试是第一步。
什么是Ab Testing?
AB测试是一种方法,通过向客户或潜在客户展示不同版本的功能、页面、按钮等,并通过一些指标(点击、购买、响应行动等)来评估交互的质量。任何时候,如果你想测试某个东西的多个变体,AB测试都是一个很好的选择。
如何开始
将过程简化为不同的步骤是很重要的。
设计,计划和运行你的实验
第一部分是设置好你的假设,或者你认为会发生的事情。(更具体来说,你认为的是备择假设(Alternative Hypothesis),而零假设(Null Hypothesis)会假设变量之间没有差异变化。)
让我们先来浏览一下你需要了解或者准备的内容:
- 备择假设(Alternative Hypothesis):这是你认为会发生的事情。例如:变量B比变量A的表现好20%。
- 零假设(Null Hypothesis):假设变量之间没有差异。
- 设定好因变量:你要决定你的功能要达到的目的是什么。比如,让用户点击下一页,让他们在购物车里加更多的东西,购买更多的商品,或者其他任何涉及多种产品的东西。无论行动要求或指标是什么,我们都将使用它来衡量变化的程度。
- 当你设计任何给定的实验时,你可能会有各种各样的自变量,你想用它们来预测Y(你的因变量);在AB测试的情况下,因变量中,变体的解释变量(explanatory variable)只会显示哪个版本会导致什么结果。
在进行实验时的另一个想法,是在相同的时间段内向客户推出变体,而不是在不同的时间段内推出不同的变体。你的样本中中出现越多的非随机变化,你的实验就越不可靠。时间是一个标准化的好例子,不要让季节性(seasonality)变化在你的实验结果中发生影响。当你启动一个实验时,要启动它的所有变体。
到这一步,人们最常问的一个问题是,每种变体需要多少样本,才能得到有统计意义的结果?
为了确定这一点,我们进行了所谓的功效分析(power analysis)。功效分析的原理是根据一系列参数来确定所需的样本量;比如统计能力,p值,变量的数量,以及两组测量的差异大小等。这样做的原因是为了确保实验时间不会太长,以至于让很多客户看到了糟糕的版本,但仍然有足够的时间去证明我们的结果是正确的。
我会在接下来给你做详细说明。
- K – 变体数(number of variants);至少两个,但可以更多。你需要记住的一点是,变体越多,需要的数据就越多。
- n – 每组样本容量,我们把这个留作NULL,这就是我们要解决的部分。
- f – 我们想要验证的组之间观察到的差异:差异越大,需要的样本就越小,差异越小,需要的样本就越大。从我生成的样本数据来看,最小的可测距离为18.7%
- 显著性水平(significance level):这个数的意思是,如果结果成功验证了你的假设,我们可以接受的随机的可能性是多少;通常,我们用的数字是0.05。
- 统计功效(statistical power):如果你的假设是真的,你最终接受它的概率是多少。标准通常是0.8。
让我们加载pwr包,然后用pwr.anova.test来确定所需的样本大小。
我创建了两个虚拟数据集,一个用于实验,一个用于预实验。
library(pwr)
pwr.anova.test(k = 2,
n = NULL,
f = .202,
sig.level = 0.05,
power = .8)
作为参考,我还将提供一段代码,你可能会用到这些操作来达到对基线的理解。基线在这里是变量A。
pre_experiment_data %>%summarize(conversion_rate = mean(call_to_action))
正如你在上面看到的,每个变量的n(样本数)是98。
click_data %>%summarize(conversion_rate = mean(clicked_adopt_today))
返回的结果是0.502,作为我们的基线,来与变体B的0.673进行比较。
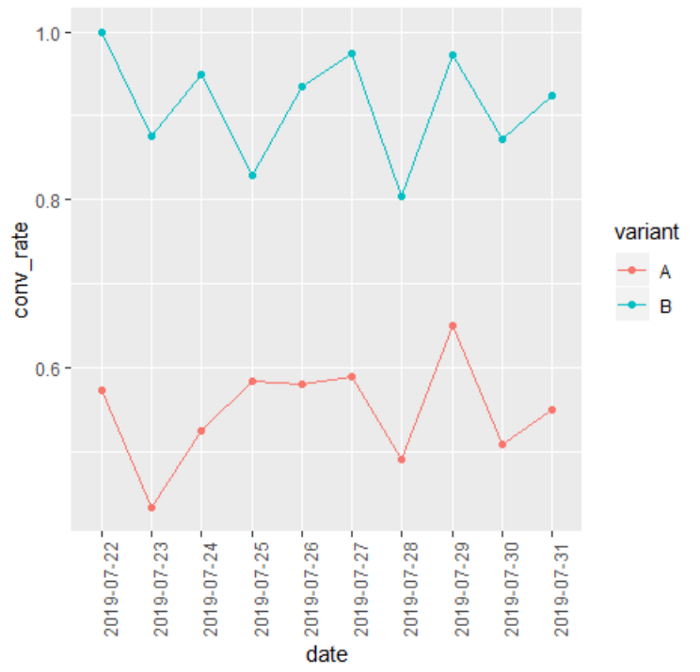
另一种选择是在实验过程中绘制不同变体的性能图表。下面你可以看到,我们按日期和变体对实验数据进行分组,然后汇总并画出每组的平均转化率。由于这只是示例数据,为了可视化的展示,我对数据进行了调整。
experiment_data %>%group_by(date, variant)%>%summarize(conv_rate = mean(call_to_action))%>%ggplot(aes(x = date,y = conv_rate,color = variant,group = variant)) +geom_point() +geom_line()+theme(axis.text.x = element_text(angle = 90, hjust = 1))
验证和分析你的结果
在每个变体中收集了114个样本之后,就可以验证结果了。
在通过GLM导入度量之前,你可以直接查看实验数据,并检查按变量分组的度量的转换率。
experiment_data %>%group_by(variant) %>%summarize(conv_rate = mean(call_to_action))
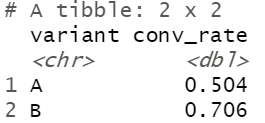
结果和我们之前看到的差不多,这是个好迹象。
另一个选择是去看实验过程中不同变体的表现。
现在,我们用GLM验证这个结果。
正如你在下面的语句中所看到的,我们试着通过它们的经验变体来解释call_to_action的结果。末尾的tidy()函数只是清理了输出,要用这个函数,需要先下载broom软件包。
glm(call_to_action ~ variant,family = "binomial",data = experiment_data)%>%tidy()

首先我们来看variantB的行,你可以看到p值低于我们的最小值.05.
现在,将intercept的估计值与variantB进行比较,可以看到,我们的测试组比对照组有更高的转化率。
结论
达到这个结果后,我们就可以接受我们的假设了!现在,你可以执行你的结果,并继续相应的迭代了!
我们在很短的时间内学习了很多内容,现在,我来把今天所学的内容分解一下:
- 设计,计划和运行你的实验
- 如何选择零假设和备择假设
- ab测试相关参数的解释:k, n, f, sig.level和power
- 如何进行实验并验证我们的结果
拥有强大的AB测试基础是数据科学家工作的关键,特别是那些产品组织内部,并希望利用他们的技能来推动有意义改进的人。
Data Science-ing快乐!
原文作者:Robert Wood
翻译作者:过儿
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/ab-testing-fundamentals-for-every-data-scientist-34afa436ce0e

如何成为一名全栈开发员(Full-Stack-Developer)?
许多成功的专业技术人员都曾做过前端或后端网站开发员。如果你能成为一名全栈开发员,更是可以在这个瞬息万变的市场中大幅彰显你的市场性和可变性。


数据分析求职最常用的30种大数据工具,你掌握几个了?
大数据处理分析能力在21世纪至关重要。使用正确的大数据工具是企业提高自身优势、战胜竞争对手的必要条件。下面让我们来了解一下最常用的30种大数据工具。