

谷歌是世界上最大的科技公司之一,成立于1998年,拥有著名的搜索引擎。现在,谷歌拥有250多种与互联网相关的服务和产品,包括硬件、软件、在线广告和云计算。
它与Facebook、亚马逊、苹果和Netflix一起,是美国五大IT公司的一员,在全球拥有近14万名员工。
在本文中,我们一起来看谷歌数据科学家面试中的题目,并通过一个简单的解题步骤来回答它,你也可以把这个技巧应用于其他数据科学挑战。本文中,你可以了解我们是如何构建并执行一个框架,然后通过符合逻辑的、可管理、和可操作的步骤去解决数据科学面试中的题目的。
谷歌的数据科学职位
数据是谷歌大部分产品的主要输入和输出内容。因此,数据科学家会在谷歌的许多团队中工作,包括财务、运营、工程、销售、支持、营销、战略和人事等部门。这也意味着数据科学职位具有各种各样不同的岗位职责,具体取决于你将和哪个团队合作。
谷歌的数据科学家职位需要掌握各种统计类软件技能,包括R或Python、SQL等数据库语言、机器学习、统计数据分析、数据建模等。通常还需要通过查看大量数据来获得见解、进行跨职能交互、为谷歌产品提供业务建议等等。
谷歌数据科学家面试问题中的概念测试
在谷歌数据科学家面试中,你必须拥有的数据库语言技能包括:
- 计数和其他聚合函数
- 根据数据的某些部分进行排序
- 对数据做出假设,并过滤不相关的字段
在本文的解决方案中,我们需要使用所有以上技能,通过解决这个问题,你将能够在面试期间或在StrataScratch平台上回答问题时,轻松地在你的代码解决方案中利用这些技巧。
谷歌数据科学家面试题目
活动排名
这是一个真实的题目,谷歌的一位数据科学家面试官要求应聘者解答。它的标题是“活动排名”,目标是找出哪些用户发送的电子邮件最多,并根据离散的电子邮件数据对用户进行排名。
问题链接:
https://platform.stratascratch.com/coding/10165-activity-rank
Google数据科学家面试题目的难度很大,因为它需要仔细、准确地使用计数聚合和排名函数。与大多数问题一样,你有几种方法可以回答,但我们希望以一种既能显示对SQL概念的掌握,又能灵活处理各种数据集的方式来解决这个问题。
解决问题的框架
有一个可重复的框架来解决数据科学问题很重要。下边是一个基本的三步框架,可以用于大部分数据科学面试问题,它涉及理解数据、制定方案和编写代码三部分。
- 1. 理解数据:包括查看面试官提供的所有电子邮件数据,并根据这些数据做出假设。如果你无法通过数据摘要理解数据,可以请面试官向你展示一些电子邮件数据案例。只需几行,就可以将值与列匹配,从而更好地理解数据列表。
- 2. 制定方案阶段:在将问题转化为代码之前,你需要制定出解决问题的逻辑步骤。想一想分析电子邮件数据所需的所有功能,然后列出它们,尽管可能此时顺序还不正确。当你构建代码大纲时,请谷歌面试官一起浏览,这样他们就能理解你的思维过程,并提供相关反馈。
- 3. 编写代码阶段:需要把之前构想的步骤转换为能运行的SQL代码。要避免解决方案过于简单或过于复杂,因为在许多情况下,这些类型的解决方案对于各种数据集可能不够通用。你需要继续向谷歌面试官讲述你的解决方案来展示你解决问题的能力。
了解你的数据
我们首先来看看谷歌提供给我们的数据,并根据这些数据建立假设。请记住,在谷歌面试期间,你并不一定能访问真实数据或执行代码。相反,你必须查看面试官提供给你的信息,以便提出假设和构思代码。
在本文的面试题目中,我们只有一个表格需要分析。

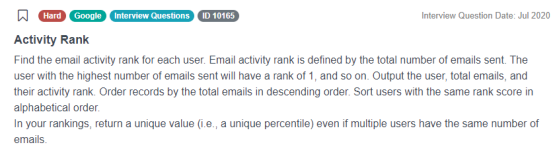
在这个Google电子邮件表中,每一行都会显示各个电子邮件交互状态。从中可以看到电子邮件来自哪个用户,发往哪个用户,以及他们发送电子邮件的日期。首先,我们可以对这些数据做出两个假设:
- 1. 我们不需要id、day或to_user列。
- 2. 我们将使用from_user作为确定电子邮件数量的列。
解决方案
制定方法
接下来,我们列出一些大概的、符合逻辑的、基本的步骤,并在稍后转变成代码。以下是我们将针对此问题执行的步骤:
- 1. 查询每个用户的电子邮件数时,忽略掉不相关的列。
- 2. 使用排名函数,如ROW_NUMBER(),按用户的电子邮件计数进行排名,并对排名进行排序。
每个用户发送的电子邮件
我们必须将这些常规步骤转化为有效的SQL代码。首先查询google_gmail_emails表,统计每个用户发送的邮件数量。我们已经假设放弃SELECT语句中的id、to_user和day列。作为查询的一部分,我们使用COUNT()聚合函数来计算电子邮件的总数,并且,与任何聚合函数一样,我们必须通过GROUP BY进行分组,在这个表中,该列是from_user。
SELECT from_user,COUNT(*) AS total_emailsFROM google_gmail_emailsGROUP BY 1
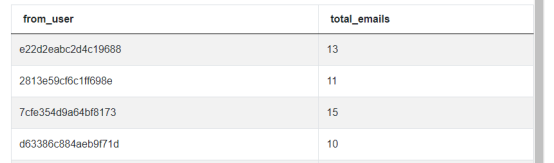
用这个代码,我们得到了每个用户的电子邮件总数。然而,我们可以看到它并没有按任何顺序排列,所以下一步我们需要按照正确的顺序对其进行排序。
每个用户的电子邮件总数排名,并对排名排序
排名顺序的需求非常明确,因此每一行的排名必须是唯一的,并对总电子邮件计数按降序排序。
对于排序,我们将使用ROW_NUMBER()函数来避免跳过或重复排名。使用排序函数,通常必须按照数据的排序进行排名,在这个解决方案中,我们将再次使用COUNT(*)聚合函数按照电子邮件总数的降序进行排名。
SELECT from_user,COUNT(*) AS total_emails,ROW_NUMBER() OVER (ORDER BY COUNT(*) DESC) AS ntileFROM google_gmail_emailsGROUP BY 1
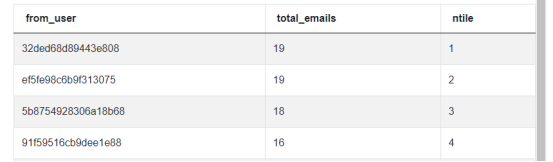
现在,我们成功得到了有序的电子邮件总数的排名,这也是正确的输出。
结论
在本文中,我们用一个简单的查询语句,解决了一个谷歌数据科学家的面试题目。虽然还有其他几种方法可以解决这个问题,但我们提供了一个最简单、最有效的解决方案。
你还可以挑战一下自己,比如在本题中,再查询一下每个电子邮件占总数的百分比。看看你能否想出更具创造性、效率更高或更简单的替代解决方案。感谢你的阅读!
原文作者:Nathan Rosidi
翻译作者:Lia
美工编辑:Chuang Zhang
校对审稿:Jiawei Tong
原文链接:https://nathanrosidi.medium.com/google-data-scientist-interview-questions-212dac2b3127

数据岗位大合集|DS、DA、BA和DE的区别及求职面试重点
随着数据行业近几年的持续火爆,各种相关职位五花八门的出现。作为一名数据科学家Data Scientist,经常被误认为是 Data Analyst。

