

在我本科时参加的第一节数据科学课上,我们的教授向我们展示了下面的维恩图。我已经找不到最原始的图片,所以我尝试自己制做了这份图表,尽力把重点内容给大家展示出来。
现在回想,她选择用这张图片教育我们,想让我们记住数据科学的核心基础,因为现在,世界正逐渐被来自硅谷的光彩夺目的产品吸引。
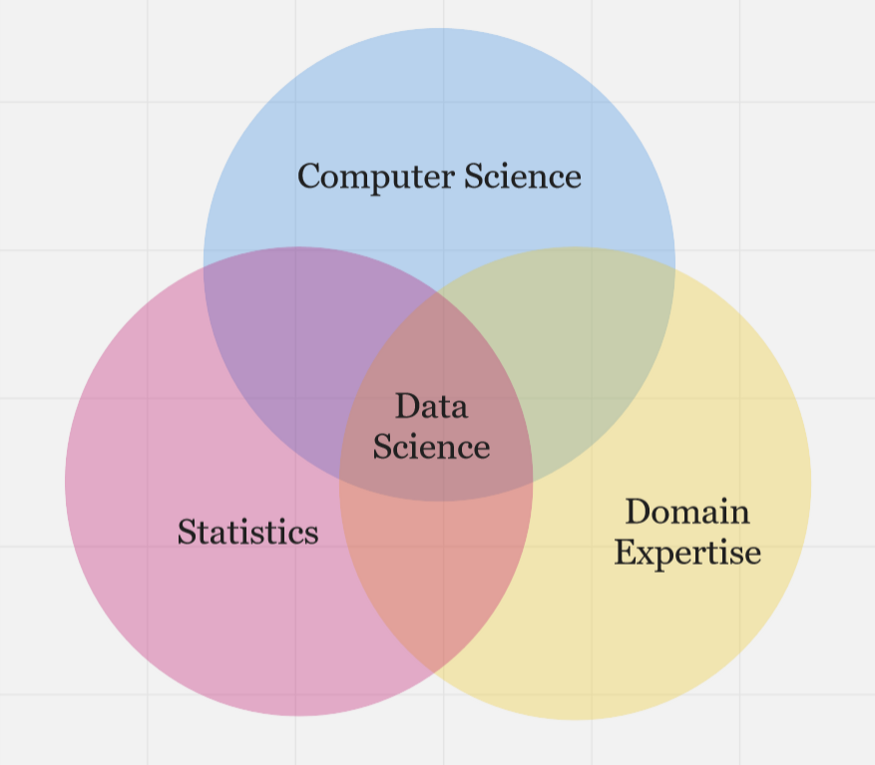
如今,似乎每个人都在关注一些热门的数据科学新话题或技术,无论是PyTorch、TensorFlow、最新的Tableau更新,还是谷歌最先进的自然语言处理模型。所有这些主题有什么共同点呢?毫无疑问,它们都是技术性(technical)的。
别误会我的意思。我想说, 技术专长当然是有效数据科学工作的重要组成部分,但它不是唯一的组成部分。就本质而言,数据科学是一个跨学科领域。要想在这方面出类拔萃,重要的是要从它的所有基本学科中汲取经验。
在这篇文章中,我将介绍数据科学的三个组成部分——统计学、计算机科学和主要专业技能——并讨论每一部分对数据科学的重要性,以及探讨如果忽略一个或多个组成部分,会出现什么问题。
统计学
我们中的大多数人可能会把“统计学”这个词抛来抛去,用来支持我们的随机论点,但我们真的能讲出它的含义吗?根据牛津词典,统计学是“大量收集和分析数字数据的实践或科学,尤其是为了从代表性样本中推断整体比例的目的”[1]。
简单来说,统计学会研究一系列数字,并试图从中找到有意义的模式。它通常分为两个分支:
1)描述统计学(descriptive statistic),试图描述现有数据中的模式;
2)推理统计学(inferential statistics),试图对未来数据进行预测。
在原始定义中,有两个重要方面需要注意:
- 1. 传统意义上,统计学作为数学的一个分支,主要专注于严格的数字数据。我们在下文中可以看到,数据科学并不一定如此。
- 2. 准确的统计数据必须靠有代表性的样本。这与第1点有关,因为盲目关注数字可能会适得其反。
在数据科学出现之前,统计学就是数据科学。几个世纪以来,人们一直在分析数据来获取见解,但正式的数据科学是一个相对较新的领域。为什么?在过去,数据是手工收集的,数量相对较少,这意味着我们可以手工分析。然而,随着计算机的出现,我们可获得的数据量呈指数级增长,仅靠统计数据已不足以对其进行处理和研究。
这就引出了现代数据科学的下一个组成部分。
计算机科学
回到我们的好朋友牛津词典,它把计算机科学定义为“研究计算机的原理和使用”。
嗯,信息量不大。但甚至可以说有点误导。
许多人把计算机科学默认等同于编程或软件工程。实际上,计算机科学涉及一系列不同的学科——包括但不限于图形学、理论计算机科学、操作系统、计算机体系结构、算法设计和编程语言。
将所有这些领域联系在一起——从而将计算机科学定义为了一个整体——是使用计算机程序来一步一步地执行逻辑运算,从而解决问题。事实上,这就是“计算机”——一台执行一系列逻辑运算的机器。计算机科学是在追求特定目标的过程中,对这些运算的积极操作。
计算机最大的优点是,它们比人类执行计算的速度快得多。这就是计算机科学是数据科学的主要组成部分的主要原因。
理论上,数据科学可以在没有计算机的情况下存在。计算机不能提供分析数据的数学基础——这就是统计的作用。在一个人类可以以光速进行思考和写作的世界里,统计学可能就足够了。
但在实践中,数据实在太多,我们不可能用手去收集、研究、处理和分析所有数据。有了计算机科学,这将是大大促进大数据洞察力的现代工具。

在这一点上,我们可以看到,统计学为数据科学提供了数学基础,计算机科学为数据科学提供了现实世界的处理能力。
然而,如果没有第三个同样重要的因素,前两个因素都会失去意义。
领域专长
这一次,我没有牛津词典的定义可以借鉴,因为领域专长并不是一个单一的领域;它更像是一个概括性的术语,我们可以用下面的方式来理解。
让我们问自己一个问题:在谈论数据科学时,数据实际上是来自哪里的?它是某个统计方程的数学余项吗?还是隐藏在计算机硬件某处的难以捉摸的构造?
这些看起来像是很蠢的问题,但是当我们看到这么多数据科学家如此痴迷于数字和代码,而忘记了他们这两个方面的成功是从根本上依赖于数据本身时,它们就变得不那么愚蠢了。
这些数据来自哪里?不同领域。
如果没有正确理解数据的环境,数据就毫无价值——环境只能由领域的专家得出:理解数据来源领域的人,才能够提供正确解释数据所需的视角。
让我们用一个玩具的例子来说明这一点。想象一下,我们从最近几年的PGA巡回赛中收集了一系列不同的高尔夫比赛的数据。我们获取所有数据,进行了处理和组织,分析,对所有公式和计算进行了三次检查,然后自信地公布了我们的发现。
再然后,我们成了媒体的笑柄。为什么?因为我们都没有真正打过高尔夫球,所以我们没有意识到分数越低,表现越好。因此,我们所有的分析都是基于相反的结果,因此是不正确的。
当然,这个例子显然是夸张了,但它可以让人明白重点。数据只有在正确的领域环境中才有意义,因此,在尝试得出任何结论之前,你必须咨询这个领域的专家。
在实践中,不考虑领域、持续依赖纯定量方法可能会导致不道德的、限制性的数据科学实践。
最后的想法
六个月前,当我开始攻读数据科学博士课程时,我与系里的一位教授进行了一次交流。就背景而言,他有社会学背景。
有几个同学约他一起喝咖啡,讨论研究的方向;我正好碰到他们,他问我的研究方向是什么。我回答说,我学习了以人为中心的数据科学、计算机科学教育、和可视化。
他注意到了我回答中的第一点,然后简要讨论了他的研究项目是如何围绕技术的历史和社会学展开的。他描述了他是如何研究信息技术的基础设施,并对通过提供数据和计算工具,来支持科学活动(是不是听起来很耳熟?)。
最后,他半开玩笑地笑着说:“所以,我自己也算是一个以人为中心的数据科学家。”
当时,我没怎么把这件事放在心上,但在过去的六个月里,我开始真正明白他的意思。他的角色是推动和支持领域专家,可以让人们在不同领域中正确地理解和解释他们的数据——而这项工作的重要性怎么强调都不为过。
在这一点的基础上,让我们来回顾一下整篇文章:
- 1. 统计学提供了从数据中获得数学见解所需的工具。没有它,我们就有可能得出科学上不严谨的结论。
- 2. 计算机科学提供了大规模收集、处理和分析数据所需的工具。没有它,我们就不能理解现代世界中可供我们使用的大量数据。
- 3. 领域的专业知识提供了情境化和理解数据所需的工具。没有它,我们就有可能因为仅仅依靠数学和计算技术而得出不准确的结论,而这些技术忽略了只有领域的专家才能看出门道的复杂数据。
将这三者结合起来,我们就得到了数据科学。
参考文献:
[1] https://languages.oup.com/google-dictionary-en/
原文作者:Murtaza Ali
翻译作者:Chuang Zhang
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/the-three-building-blocks-of-data-science-2923dc8c2d78


