

随着企业数据量的爆发式增长,企业对专业数据人员的需求也在增长。具体来说,对精通SQL而非初学者水平的专业人员的需求日益增长。
因此,我和StrataScratch的创始人Nathan Rosidi回顾了我认为最重要的10个中高级SQL概念。
1 公用表表达式 (CTE)
如果你想要在查询中查询,这时候就可以使用CTE——CTE本质上是创建一个临时表。
使用公用表表达式(CTE)可以模块化代码和分解代码,就像你将一篇文章分解成几个段落一样。
考虑以下查询,其中包含where子句中的子查询。
SELECT name
,salary
FROM People
WHERE name in (SELECT DISTINCT name
FROM population
WHERE country = "Canada"
AND city = "Toronto")
AND Salary >= (SELECT AVG(salary)
FROM photos
where gender = "Female")这似乎不难理解,但是如果子查询中有很多子查询或者子查询中嵌套子查询呢?这就是CTE发挥作用的地方。
with toronto_ppl as (
SELECT DISTINCT name
FROM population
WHERE country = "Canada"
AND city = "Toronto"
)
, avg_female_salary as (
SELECT AVG(salary) as avgSalary
FROM salaries
WHERE gender = "Female"
)
SELECT name
, salary
FROM People
WHERE name in (SELECT DISTINCT FROM toronto_ppl)
AND salary >= (SELECT avgSalary FROM avg_female_salary)现在很明显,WHERE子句正在筛选在Toronto的姓名。CTE很有用,因为你可以将代码分解成更小的块,它们允许你为每个CTE分配一个变量名(即toronto_ppl 和avg_female_salary)
同样,CTE可以使用更高级的技术,例如创建递归表:
2 递归CTE
递归CTE是引用自身的CTE,就像Python中的递归函数一样。递归CTE在查询组织结构图、文件系统、网页之间的链接图等分层数据时特别有用。
递归CTE有3个部分:
- 定位成员(Anchor Member):返回CTE基本结果的初始查询
- 递归成员(Recursive Member):递归查询引用CTE.this与定位成员UNION ALL
- 停止递归成员的终止条件
下面是一个递归CTE示例,它获取每个员工ID的经理ID:
with org_structure as (
SELECT id
, manager_id
FROM staff_members
WHERE manager_id IS NULL
UNION ALL
SELECT sm.id
, sm.manager_id
FROM staff_members sm
INNER JOIN org_structure os
ON os.id = sm.manager_id3 临时函数
如果你想了解更多关于临时函数的信息,请查看此内容,但如何编写临时函数很重要,原因如下:
- 它允许你将代码块分解为更小的代码块
- 这对于编写更简洁的代码很有用
- 它可以防止重复并允许代码重用,这类似于在Python中使用的函数。
考虑以下示例:
SELECT name
, CASE WHEN tenure < 1 THEN "analyst"
WHEN tenure BETWEEN 1 and 3 THEN "associate"
WHEN tenure BETWEEN 3 and 5 THEN "senior"
WHEN tenure > 5 THEN "vp"
ELSE "n/a"
END AS seniority
FROM employees相反,你可以利用临时函数来捕获CASE子句。
CREATE TEMPORARY FUNCTION get_seniority(tenure INT64) AS (
CASE WHEN tenure < 1 THEN "analyst"
WHEN tenure BETWEEN 1 and 3 THEN "associate"
WHEN tenure BETWEEN 3 and 5 THEN "senior"
WHEN tenure > 5 THEN "vp"
ELSE "n/a"
END
);
SELECT name
, get_seniority(tenure) as seniority
FROM employees有了临时函数,查询就简单多了,可读性更强,而且还可以重用seniority函数!
4 使用CASE WHEN透视数据
你可能会看到许多使用CASE WHEN语句的问题,因为它用途广泛。如果你想根据其他变量分配某个值或类,它允许你编写复杂的条件语句。
鲜为人知的是,它还允许你透视数据。例如,如果你有一个月份列,并且想为每个月创建一个单独的列,你可以使用CASE WHEN语句来透视数据。
Initial table:
+------+---------+-------+
| id | revenue | month |
+------+---------+-------+
| 1 | 8000 | Jan |
| 2 | 9000 | Jan |
| 3 | 10000 | Feb |
| 1 | 7000 | Feb |
| 1 | 6000 | Mar |
+------+---------+-------+
Result table:
+------+-------------+-------------+-------------+-----+-----------+
| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue |
+------+-------------+-------------+-------------+-----+-----------+
| 1 | 8000 | 7000 | 6000 | ... | null |
| 2 | 9000 | null | null | ... | null |
| 3 | null | 10000 | null | ... | null |
+------+-------------+-------------+-------------+-----+-----------+示例问题:编写一个SQL查询来重新格式化表,以便每个月都有一个收入列。
5 EXCEPT与NOT IN
EXCEPT和NOT IN的操作几乎相同。它们都用于比较两个查询/表之间的行。虽然如此,你应该知道两者之间的差别。
首先,EXCEPT过滤掉重复项并返回不同于NOT IN的不同行。
其次,EXCEPT要求两个查询/表中的列数相同,其中NOT IN比较每个查询/表中的单个列。
6 Self Joins
SQL自连接将表与其自身连接。你可能会认为这没有任何意义,但这种情况很普遍。在许多现实生活中,数据存储在一个大表中,而不是许多较小的表中。在这种情况下,可能需要自连接来解决特殊的问题。
让我们看一个例子。
示例问题:根据下面的Employee表,编写一个SQL查询,找出收入高于经理的员工。在上表中,Joe是唯一一个收入超过其经理的员工。
+----+-------+--------+-----------+
| Id | Name | Salary | ManagerId |
+----+-------+--------+-----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
+----+-------+--------+-----------+Answer:
SELECT
a.Name as Employee
FROM
Employee as a
JOIN Employee as b on a.ManagerID = b.Id
WHERE a.Salary > b.Salary如果你想尝试这样的练习题,请在此处查看StrataScratch !
链接:https://platform.stratascratch.com/coding?code_type=1
7 Rank vs Dense Rank vs Row Number
对行和值进行排名是一个非常常见的应用。以下是一些公司经常使用排名的例子:
- 按购买次数、利润等对最有价值的客户进行排名。
- 按销售量排名前几位的产品
- 对销售额最高的国家进行排名
- 根据观看的分钟数、不同的观众的数量等对观看次数最多的视频进行排名。
在SQL中,你可以通过多种方式为行分配“排名”,我们将通过一个示例对其进行深入研究。考虑以下查询和结果:
SELECT Name
, GPA
, ROW_NUMBER() OVER (ORDER BY GPA desc)
, RANK() OVER (ORDER BY GPA desc)
, DENSE_RANK() OVER (ORDER BY GPA desc)
FROM student_grades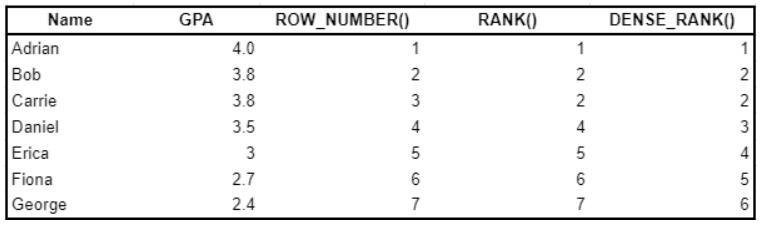
ROW_NUMBER()为从1开始的每一行返回一个唯一编号。当排名相同时(例如 Bob vs Carrie),如果未定义第二个标准,ROW_NUMBER()将任意分配一个数字。
RANK()为从1开始的每一行返回一个唯一编号,除非排名不同,否则RANK()将分配相同的编号。同样,后面将跳过重复排名。
DENSE_RANK()与RANK()类似,只是在重复排名之后没有跳过。请注意,使用 DENSE_RANK(),Daniel排名第三,而使用RANK()时排名第四。
8 计算增量值
另一个常见的应用是比较不同时期的值。例如,本月和上月的销售额之间的差值是多少?或者这个月和去年这个月之间的增量是多少?
比较不同时期的值以计算增量时,就是用到LEAD()和LAG()的时候了。
这里有一些例子:
# Comparing each month's sales to last month
SELECT month
, sales
, sales - LAG(sales, 1) OVER (ORDER BY month)
FROM monthly_sales# Comparing each month's sales to the same month last year
SELECT month
, sales
, sales - LAG(sales, 12) OVER (ORDER BY month)
FROM monthly_sales9 计算累加值
如果你知道ROW_NUMBER()和LAG()/LEAD(),这对你来说可能不会有太大的惊喜。但是,如果你不这样做,这可能是最有用的窗口函数之一,尤其是当你想要可视化增长时!
使用带有SUM()的窗口函数,我们可以计算累加值。请参见下面的示例:
SELECT Month
, Revenue
, SUM(Revenue) OVER (ORDER BY Month) AS Cumulative
FROM monthly_revenue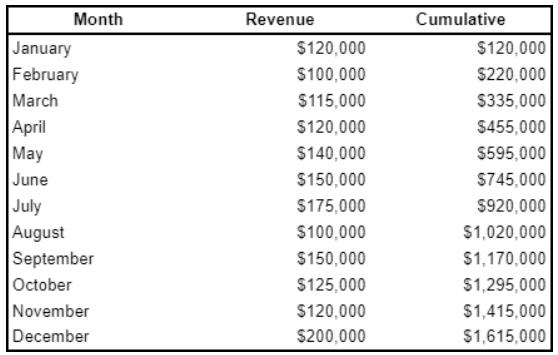
10 日期时间操作
你可能会遇到一些涉及日期时间数据的SQL问题。例如,你需要按月份对数据进行分组或将格式从DD-MM-YYYY转换为简单的月份。
你应该知道的一些功能:
- EXTRACT
- DATEDIFF
- DATE_ADD, DATE_SUB
- DATE_TRUNC
示例问题:给定一个Weather表,编写一个SQL查询语句来查找所有日期的ID,这些日期的温度比之前(昨天)日期更高。
+---------+------------------+------------------+
| Id(INT) | RecordDate(DATE) | Temperature(INT) |
+---------+------------------+------------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+---------+------------------+------------------+
Answer:
SELECT
a.Id
FROM
Weather a,
Weather b
WHERE
a.Temperature > b.Temperature
AND DATEDIFF(a.RecordDate, b.RecordDate) = 1谢谢阅读!
我希望这对你的面试准备有所帮助——我敢肯定,如果你彻底掌握了这10个概念,那么当涉及到大多数SQL问题时,你会做得很好。
原文作者:Terence Shin
翻译作者:明慧
美工编辑:过儿
校对审稿:过儿
原文链接:https://towardsdatascience.com/ten-advanced-sql-concepts-you-should-know-for-data-science-interviews-4d7015ec74b0



Twitter 遭遇人才流失
Twitter 目前正面临着一场与特斯拉首席执行官Elon Musk的潜在收购官司。据《商业内幕》(Business Insider)的一份最新报告称,Twitter 的一些员工正在成群结队地逃离公司。