

如果你的公司非常确定会有用户发布差评,你将采取哪些举措? 主动干预,改善用户体验,希望他们更改差评? 还是使用学习预测模型,解决导致用户体验感差的根本问题?
在仔细权衡投资收益、并评估公司采取更正的能力后,两个问题的答案都是“yes”。
94% 的消费者会因为“差评”,选择不和这家公司打交道”——评论跟踪器(Review Trackers)
业务问题 – 用户差评
Olist是巴西知名小型电子商务企业。Olist Store 让巴西各地的商家都能够通过 Olist 物流合作伙伴,向用户销售并运送产品。交付后,用户会收到一封电子邮件满意度调查,评分范围为 1(不满意)到 5(满意)。
Olist 公布了 2017-2018 年 10 多万笔交易的匿名用户评论及订单详细信息。该数据集已被数据科学家下载超过 76,000次。
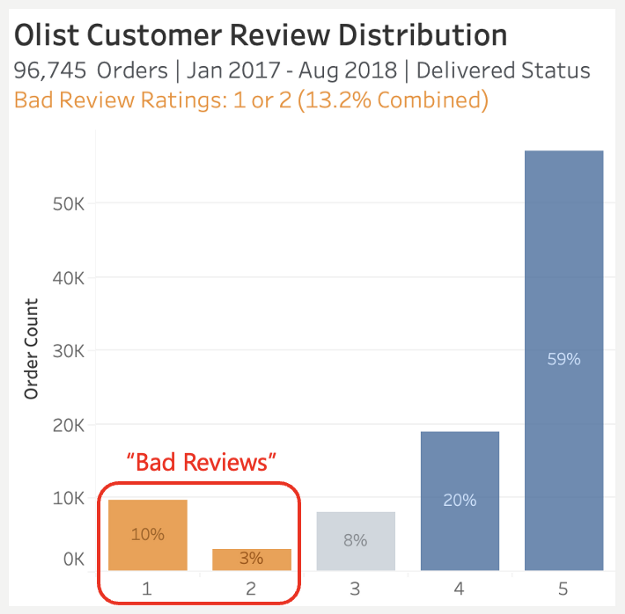
让我们根据“用户差评”构建一个预测模型,收集评分为 1 或 2 的数据(满分为5)。在交付的大量订单样本中,13.2% 的评论分数为差(负)。
我们将设置一个二元目标变量:review_bad = 1。
我们的目标是设计一种监督式机器学习分类模型,该模型可以准确预测用户差评。
高精度表明,当我们的模型预测差评时,结果通常无误。这最大限度地降低了公司对预测的用户差评采取不当行动的风险。
将数据转换为特征
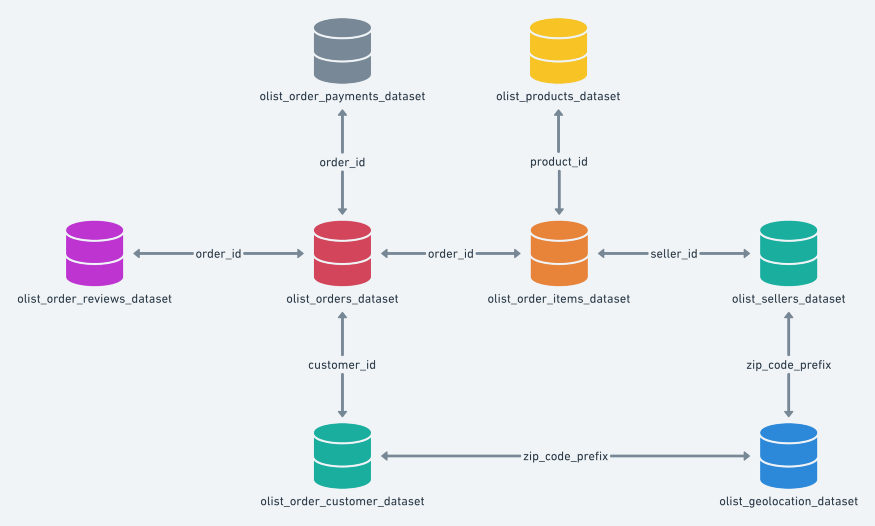
Olist提供了8个关系表数据,非常具有参考性。下图为大家熟知的数据模型,该模型包含一个单独的订单 ID,连接多个项目和每个订单的付款。主数据表包括产品、用户和卖家。用户评论与整体订单相关联,该订单可以包含多个产品或一个订单中的多个卖家。
8 个表中的原始数据包括了 52 个不同的列。我们的预测特征可以根据这些域进行分组。
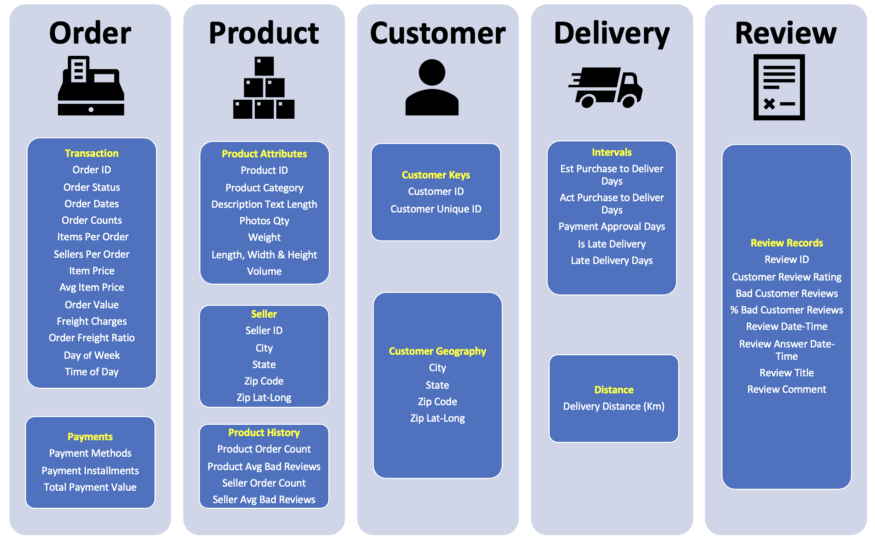
为了方便大家查看,本文不会包含全部的代码。
用于准备预测特征的数据转换包括:
- 过滤掉 2016 年的交易记录以及未交付的订单(这部分占比不到 1%)
- 填写少数存在空值的记录
- 订单、付款、产品和卖家的汇总指标,如图所示
- 使用订单中的生命周期日期计算天数间隔指标
- 使用半正弦函数中的纬度和经度中值,估算卖家和用户邮政编码之间的配送距离(以公里为单位)
- 为付款方式、用户状态、星期几和时间段(早上、下午等)创建了一个热编码变量(标志)
- 清除所有订单的评论,只保留最终评分;这部分受影响的订单占比不到 1%
视觉见解
数据分析时,我通常会将Jupyter Notebook上最终合并的数据帧导出至Tableau,方便查看。我们来看看见解中最有趣的部分。
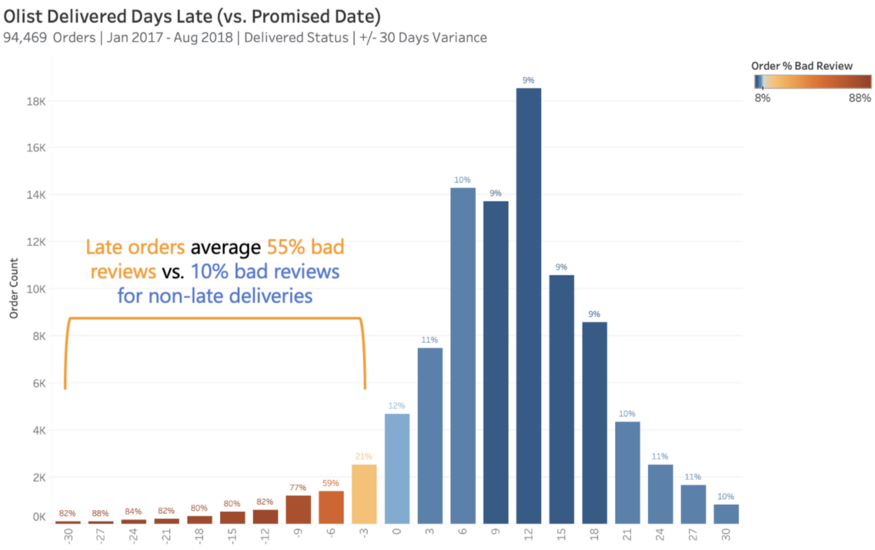
延迟交货天数(Delivered Days Late):Olist 在用户下订单时提供预计交货日期,平均为 24 个预计处理/运输天数。如上所示,实际交付天数是非常重要的。对于延迟交付的订单(与估计日期的负偏差),用户差评占 55%,而非延迟交付订单的差评占 10%。延迟天数越多,差评比例就越高。
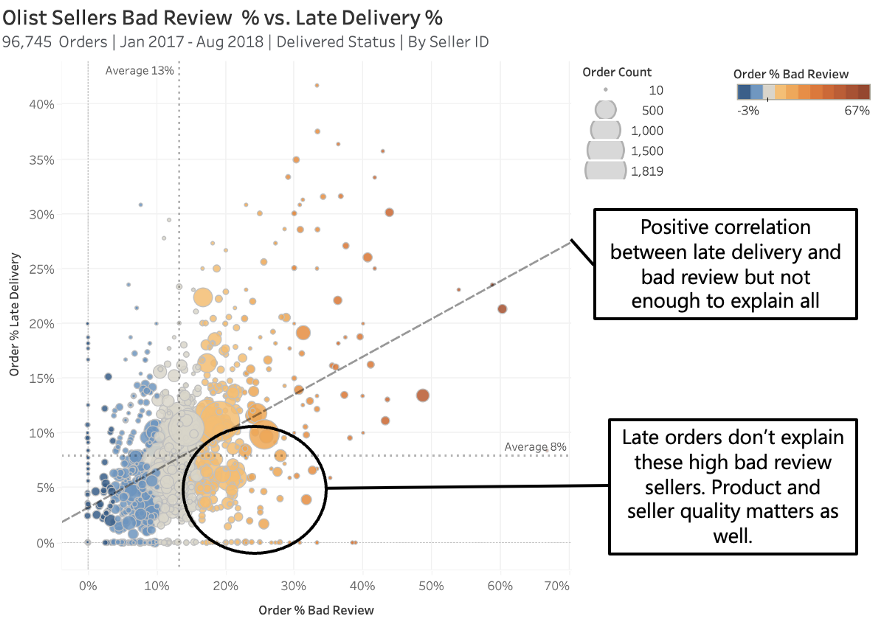
卖家-产品质量(Seller-Product Quality):散点图显示延迟交货和差评之间的线性趋势,每个观察结果都是卖家在所有用户中的平均表现。延迟订单并不是差评出现的唯一原因,因为许多卖家的交付表现高于平均水平(圈出),但差评率却依旧很高。
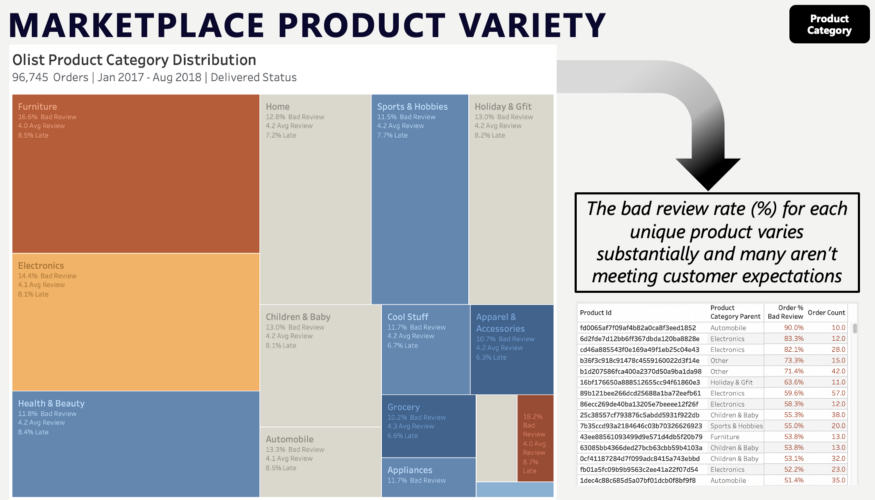
产品多样性:通过树状图,我们可以看到不同产品类别的差评率变化。深入研究某一产品,我们可以看到一些“商家”的差评超过 50%,显然这些商家没有达到用户预期。产品平均差评率是最终模型中的一个重要特征。
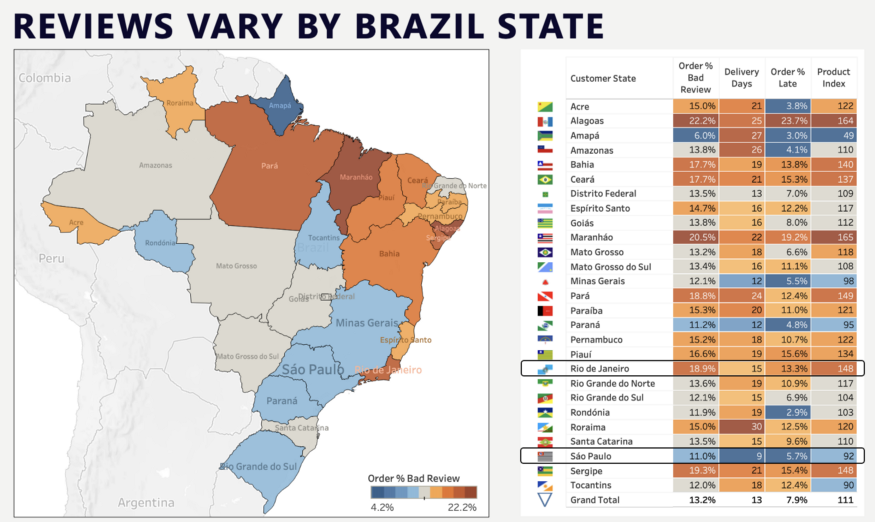
地理分布:巴西有 26 个州和 1 个联邦区。我们可以看到各州的差评存在差异。
- 圣保罗(Sáo Paulo)——该地区订单数量占 42% ,该州各项指标明显优于其他州。
- 里约热内卢(Rio de Janeiro)——该州周围地区订单占 13%,各项指标明显表现不佳。
圣保罗和里约热内卢是巴西最大的两大城市,人口密度高,距离相对较近。我们应该深入研究Rio de Janeiro(里约热内卢)交付绩效及产品组合。为什么该地区用户购买产品的差评指数高于巴西平均水平? (148 个产品指数意味着,该地区差评率比巴西平均水平多 48%)。
相关性分析(Correlation Analysis)
在 Python 中对 review_bad 目标变量运行 Pearson 相关性操作,这很大程度上证实了我们在之前的图中看到的关联性。
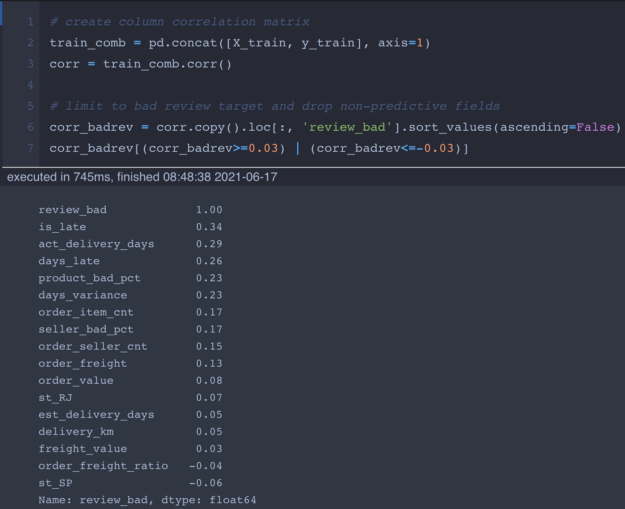
在查看单个特征相关性时,我们可以看到,所有形式的交付间隔(is_late、act_delivery_days、days_late 和 days_variance)均呈中等正相关性。
我们还发现,产品与卖家整体差评率分别呈 +0.23 和 +0.17。
最后,我们还发现其他影响订单/卖家商品数量、运费/订单价值和交货距离的因素。基于以上州图,在27个州中,只有两个州的相关系数大于0.03,分别是里约热内卢的里约热内卢(+0.07)和圣保罗(-0.06)。
预测用户差评
我们优化了七个监督学习分类模型的“精度”,计算合理的“召回率”(我们的模型正确预测了差评比例)。对于每个模型,我将网格搜索运用至80% 的训练数据,并使用分层 5 折交叉验证,探索不同参数组合。
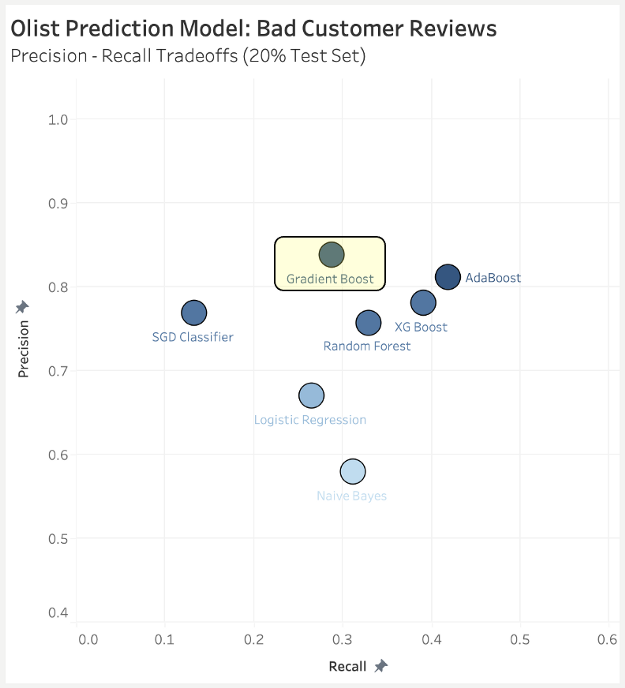
比较的模型包括了随机森林(Random Forest)、AdaBoost、Gradient Boost、XG Boost、逻辑回归(Logistic Regression)、SGD 分类器和高斯朴素贝叶斯(Gaussian Naive Bayes)。
我用StandardScaler缩放了相关特征,将同样的训练特征用作每个模型的输入值(尽管大多数模型不需要数据缩放)。
接着,将每个分类器的结果“最佳模型”应用至之前没见过的 20% 缩放测试数据,比较模型结果如上所示。
最终,我最推荐Gradient Boost模型,其性能如下:精度84%,召回率29%,准确率88%,AUC 64%。来自最佳估计器的参数为:
'learning_rate': 0.01, 'max_depth': 8, 'min_samples_leaf': 25, 'n_estimators': 100使用此模型,并将概率设置为50%的标准决策阈值,我们大约可以预测 1/3 的差评(召回),而只有六分之一的错误率(精确度、假阳性)。公司能根据以上结果采取相应措施,并不断根据过往经验及数据完善模型。
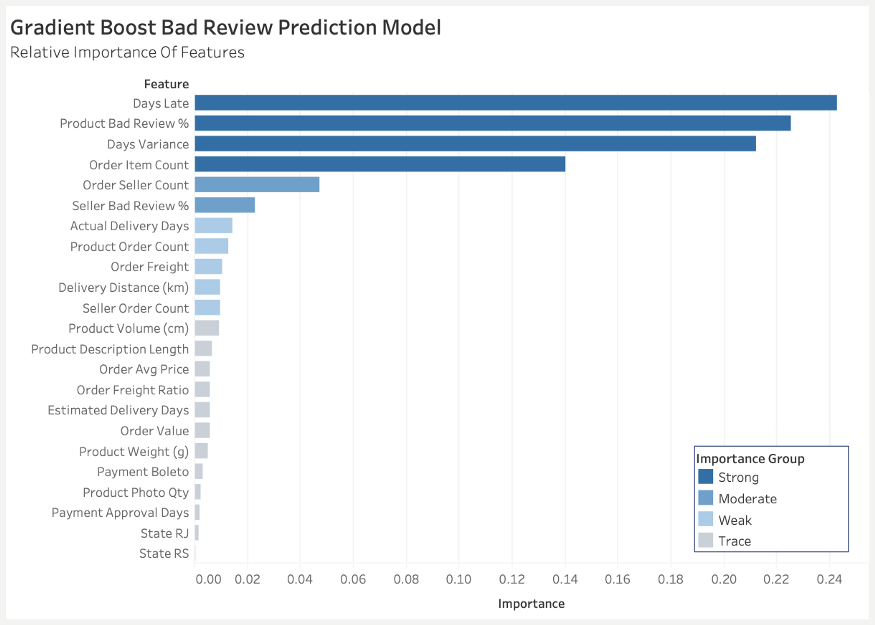
Gradient Boost 模型中最重要的特性包括:
- 最佳:延迟交货天数、天数差异、产品差评百分比、订单中的项目数
- 中等:订单上的卖家数量,卖家差评百分比
- 缺点:实际交货天数、产品订单总数、卖家订单总数、订单运费、交货距离(公里)
总结来说,差评主要是因为卖家延迟交货、产品/卖家历史以及多个卖家/产品的协调。Olist应该尝试修复传输性能不佳的根本原因。Olist 还可能尝试随机成本效益试验,看看主动沟通、确认或客户优惠是否能阻止用户不良评论。
最终,差评其实是一种礼物。这表明用户非常关心你的品牌,愿意花时间反馈意见。如果处理得当,即使是最差的评论也可以转化为一次不错的体验。— Emily Heaslip(艾米丽·赫斯利普)
数据质量观察
对该项目中数据质量和固定假设的观察。
- 样本vs.整体:10 万份订单样本都包含得分,非常适合构建模型,但不能代表整体情况。考虑到只有 5-10% 的用户发表评论,而且不是每次都会发表,我们需要转换模型,以适用于所有的Olist订单。
- 需要附加功能:虽然预测 29% 的差评的准确率为 84% ,这只是一个开始,我们需要不断优化。我建议 Olist 获取其他数据,不断开发其功能:如完整的订单数据库、用户退货、用户网络日志、用户服务交互、用户角色、人口统计、品牌/产品/卖家社交情绪、以及来自卖家的数据。
- 销售漏斗:Olist 还在 Kaggle 上发布了销售漏斗的数据集,其中包含 2 个来自卖家资格流程的上游表。当加入订单模式时,这些数据没有什么用,因为它只包含 2017 年至 2018 年之间注册的卖家,这只占此期间实际订单的一小部分(大多数都是老用户)。
感谢你的阅读!通过对这份数据集的详细推演,希望你对如何用数据预测有了更深刻的了解!
原文作者:Chuck Utterback
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/using-data-science-to-predict-negative-customer-reviews-2abbdfbf3d82


