

半数加拿大人都被新冠阴谋论蛊惑了,这实在令人痛心。WHO称,与新冠病毒相关的信息病就像病毒本身一样危险。阴谋论、谣言和夸大的事实会造成远超公共卫生范畴的后果。
多亏了Lead Stories、Poynter、FactCheck.org、Snopes和EuVsDisinfo这样的项目,我们可以监控、辨别和查验那些在全世界流传的虚假信息。
为了探索新冠假新闻的内容,我要先给真假新闻做个严格定义。一般来说,真新闻是那些来自有公信力的新闻源且公认真实的文章;假新闻是那些公认错误、由那些故意散布虚假信息的假新闻网站编造的故事。
有了以上定义后,我从多个新闻来源收集了1100多条有关新冠病毒的新闻和社交网站上的帖子,然后给他们打上标签。
数据集在这里:
https://raw.githubusercontent.com/susanli2016/NLP-with-Python/master/data/corona_fake.csv。
数据
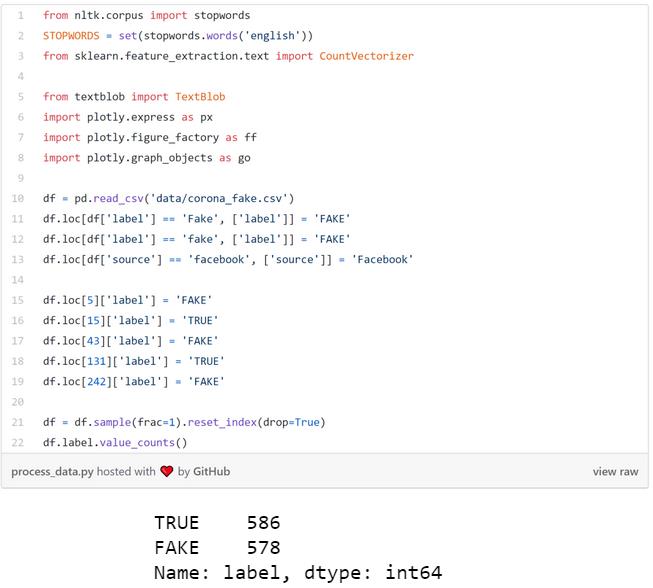
做了一些清洗之后,可以看见我们一共有586条真新闻和578条假新闻。

真新闻大部分是从Harvard Health Publishing、The New York Times、Johns Hopkins Bloomberg School of Public Health、WHO和CDC等来源收集来的。
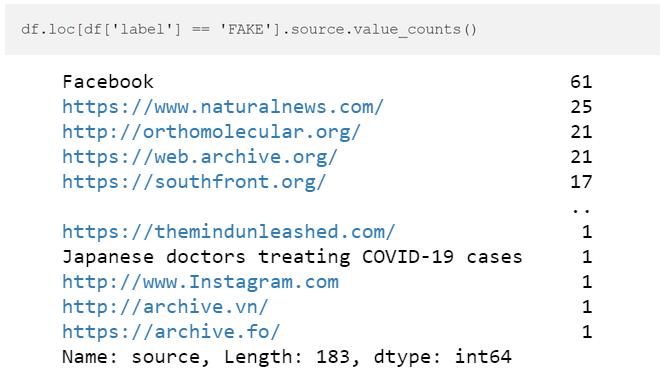
假新闻来自Facebook、一个叫Natural News的极右翼网站、一个叫orthomolecular.org的替代药物网站等等。有些文章和帖子已经被互联网和或社交网络删除了,然而,他们仍然得以进入互联网的档案封存。
使用一下函数,我们可以读取任意给定的新闻,进而决定如何对他们做清理:
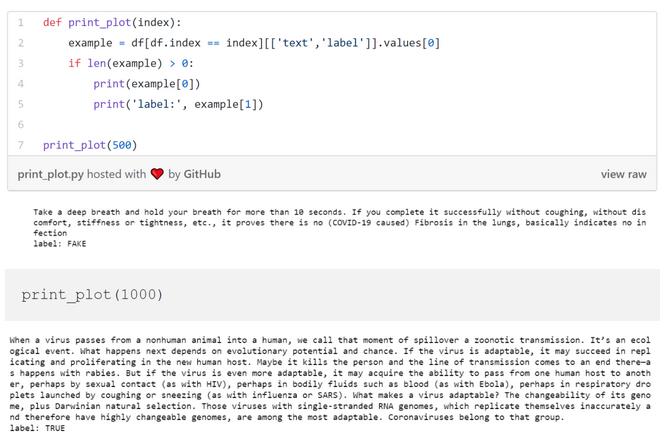
这些文章里的文本还挺干净的,我们只要去除标点符号、把字符改成小写就可以了。

文章长度
下一步我们要:
- 获取每篇文章的情绪分数,其取值范围在[-1,1],1表示真面情绪而-1则相反
- 获取每篇文章的长度(词汇数量)
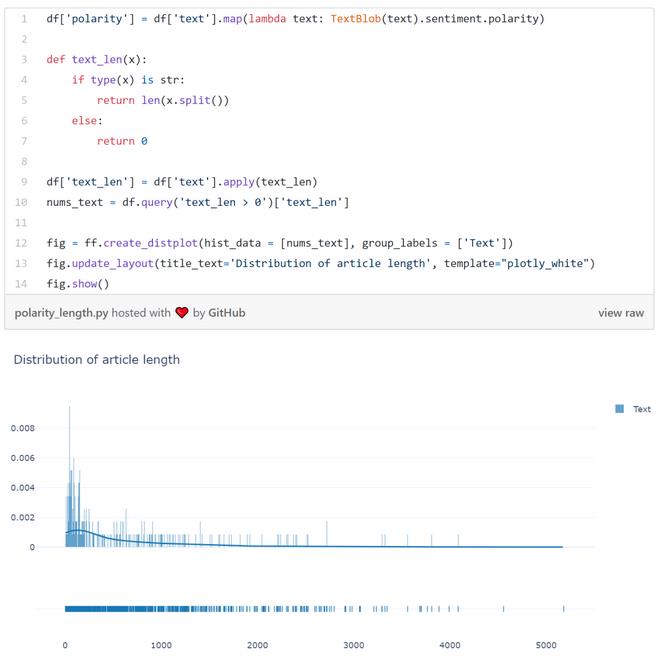
数据集内的大部分文章包含少于1000个单词。但仍有少数文章含有超过4000个单词。
按标签分开看的话,真假新闻之间并没有显著的长度差别。不过数据里的大部分真新闻看上去好像要比假新闻短那么一点。
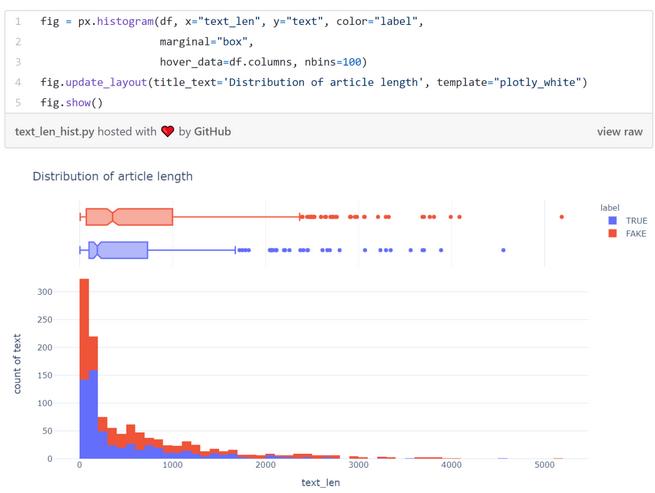
为了展示不同文本长度的概率密度,我们可以采用小提琴图:
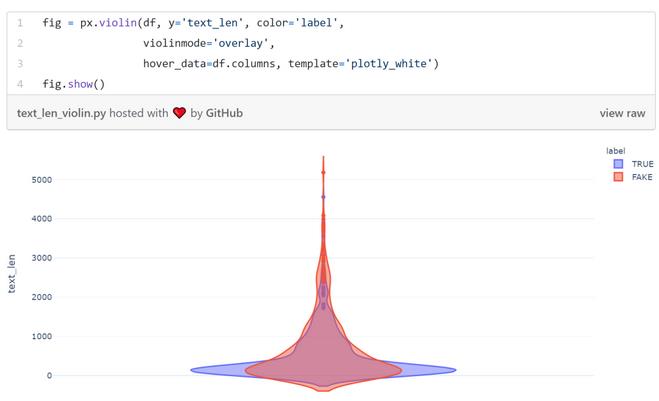
Facebook VS. Harvard
平均来看,脸书上的帖子要显著短于哈佛的卫生类文章:
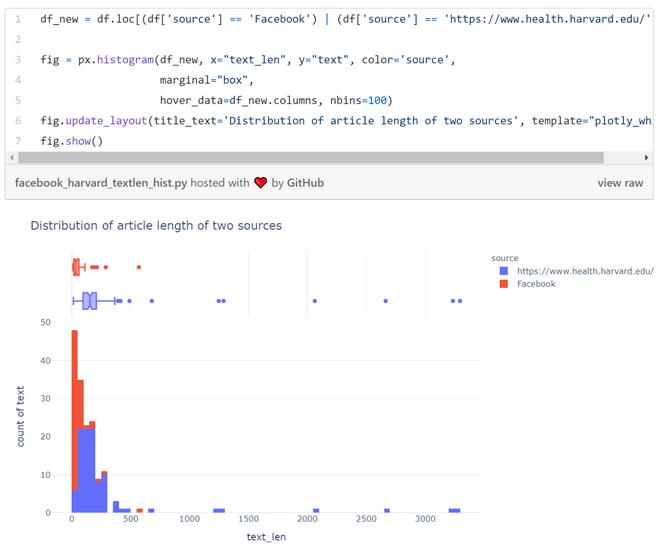
这也可以用小提琴图来展示:
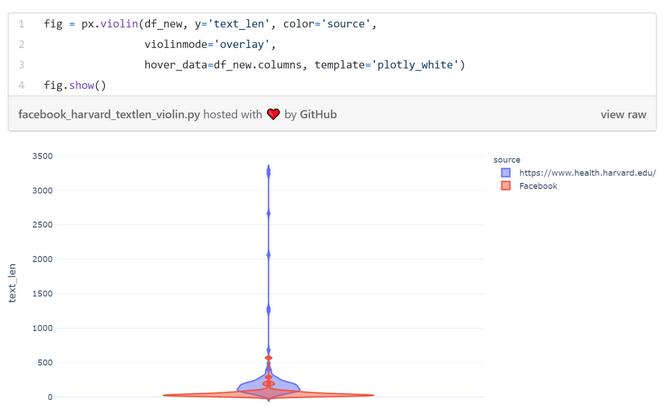
大家可能很熟悉了,脸书上的虚假帖子内容往往较短。那些发布人试图用启发而不是论点的力量来说服读者。
情绪极性
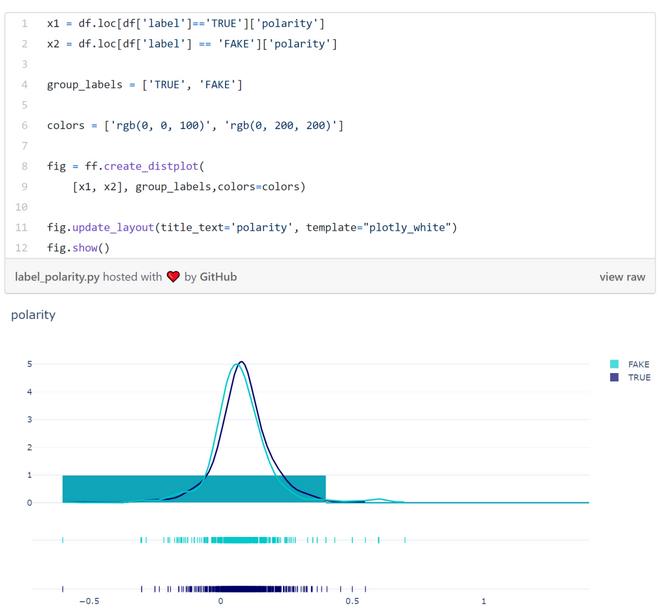
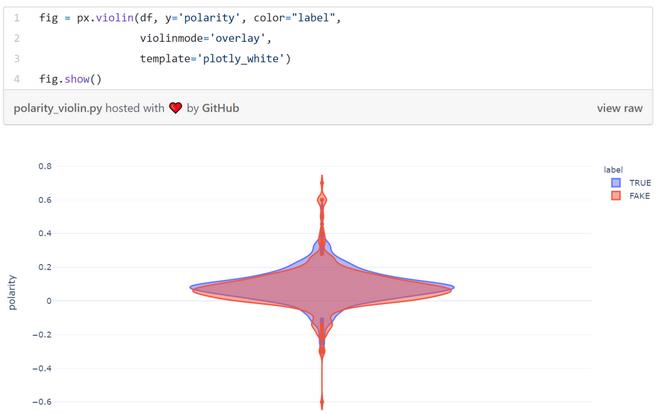
真假新闻在情绪上也没有显著区别。通过以下小提琴图可以进一步验证这一点:
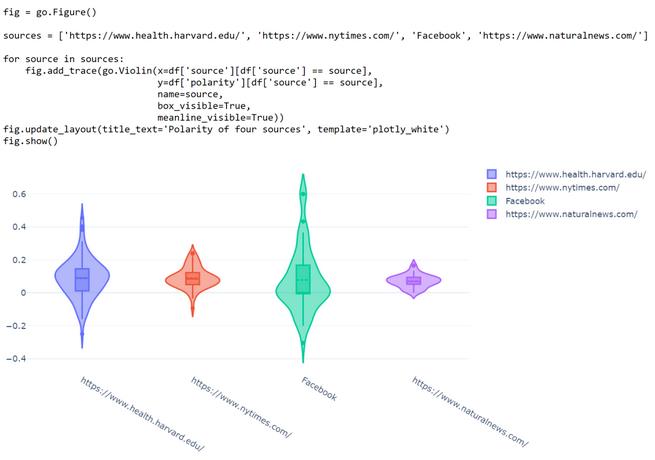
如果我们比较这四个新闻来源的情绪极性,可以看到纽约时报和自然新闻的情绪分布比哈佛健康新闻和脸书的要窄得多。
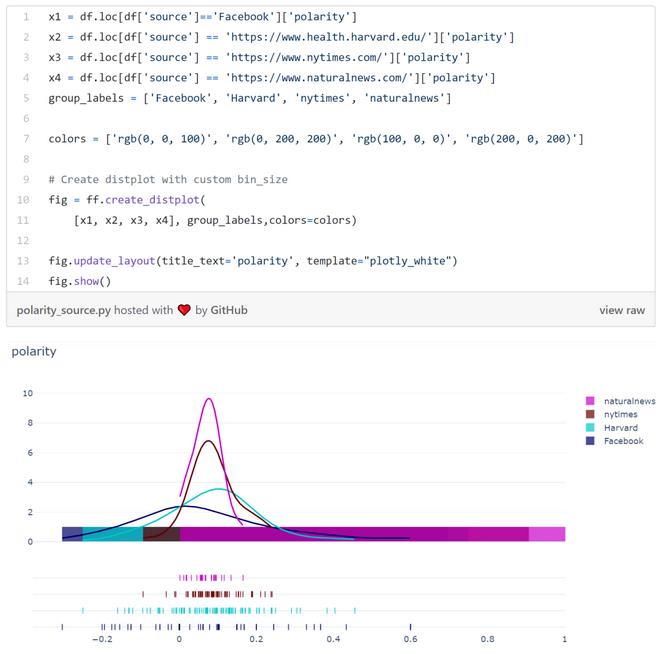
这意味着数据里纽约时报和自然新闻的文章要更不带感情一些。
可以用以下小提琴图验证:
情绪vs.文章长度vs.真实性
我注意到我收集的这些新闻文章和帖子既没有情绪特别正面的,也没有特别负面的。他们中大部分处在略微正面的范围内,同时大多数单词量都在1000个以下。
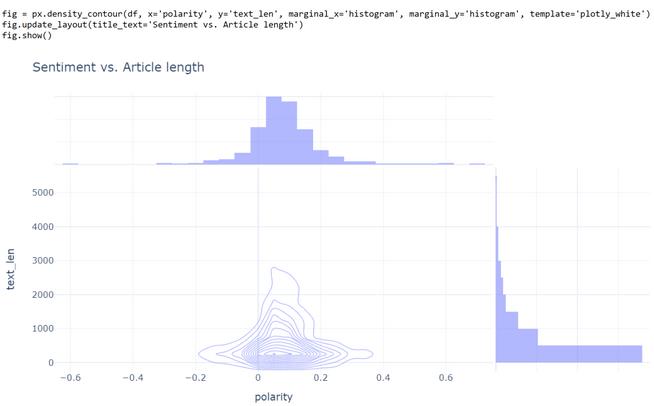
文章情绪和长度之间没有明显的相关性。整体上,文章的情绪和长度也并不反映出其真实性。真假新闻的主要区别可能在于某些随机因素。
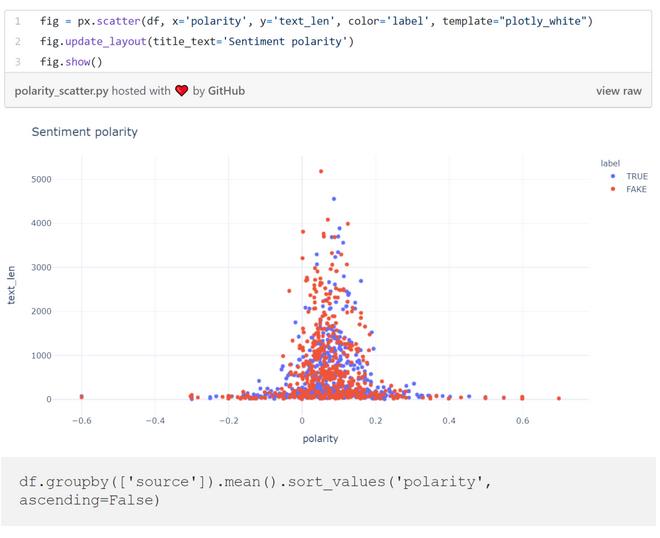
我发现Rudy Giuliani的帖子是情绪分最高的之一,我有点好奇它究竟讲了什么:
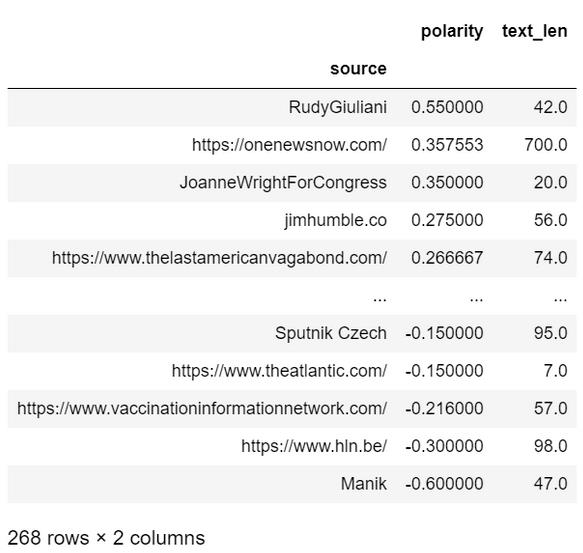
当然,是关于氢氧奎的。
真假新闻的内容
现在该理解以下我们数据中包含的主题了。
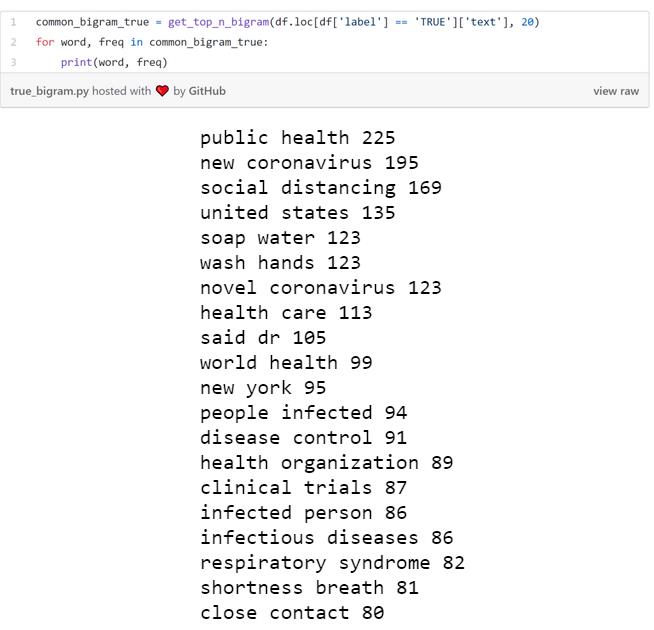
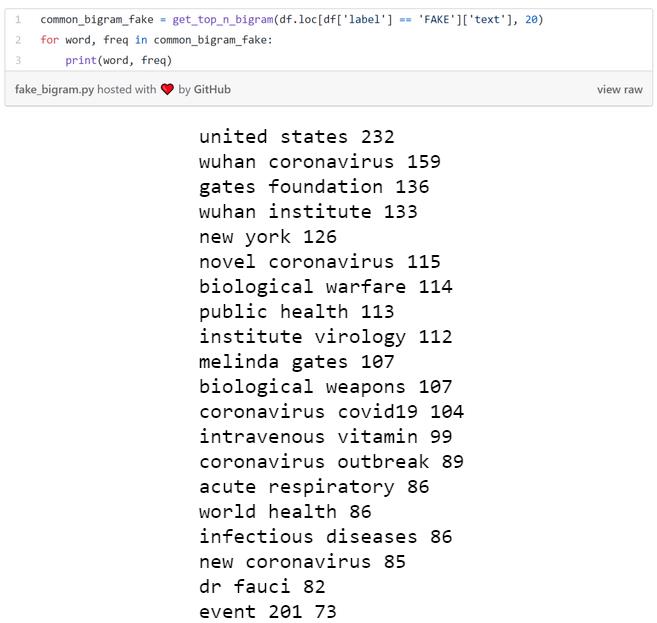
- 疗法推广:该主题包括大剂量静脉注射维生素C。
- 推测起源:该主题包括声称新冠病毒是实验室为研究生物武器而创造的或是由5G技术引起的。
- 对公众人物造谣:比如新冠病毒是比尔盖茨和福奇博士的计划,代表制药企业的利益。
- 操纵人们的恐惧:比如梅琳达盖茨基金会和约翰霍普金斯大学早在3个月前就通过201事件预测了新冠病毒。
在我们的数据中,真假新闻内容上的一个明显区别就是假新闻似乎更多地使用人的名字,这暗示着假新闻可能会更加得个人化。
naturalnews.com vs. orthomolecular.org
以上两个新闻源都在推广阴谋论,然而,他们侧重的主题却不同。
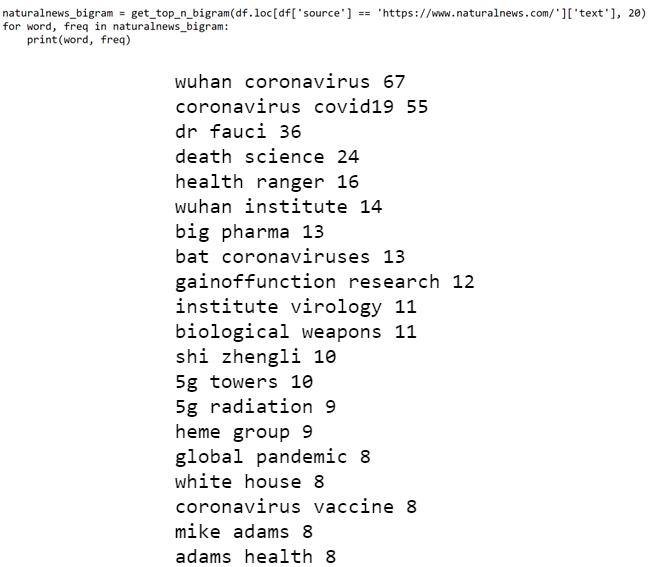
自然新闻主要传播‘新冠是中国生物武器’和‘病毒是为了掩盖5G技术对健康的有害影响而被故意散播的’之类的虚假信息。
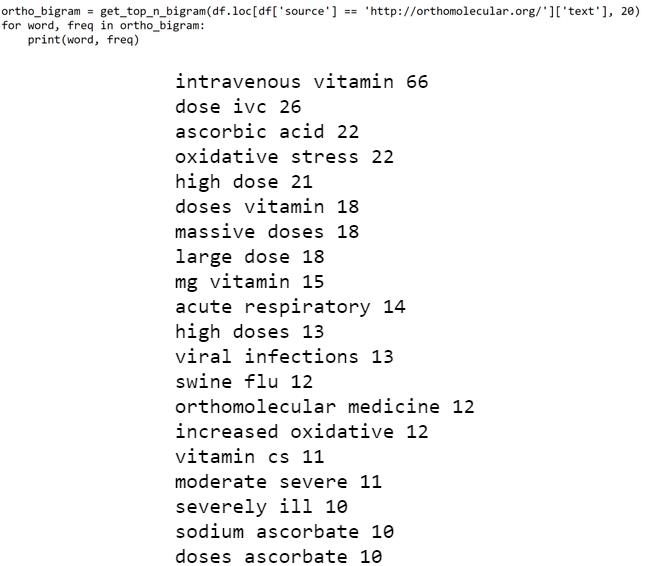
后者则侧重推广静脉注射大剂量维生素C的治疗方法,然而该方法并没有什么根据。
有了我的数据,你也可以自己查看一下其它新闻来源的情况。
总 结
首先,我们尚不知道数据收集过程中是否由选样偏差。第二,虽然我们可以确认这些新闻都是有较高用户参与度的,但是却没法知道各个新闻究竟产生了多少实际流量。尽管有这些不足,该数据集仍然提供了合理的基本事实标签,并且我们知道所有这些新闻都是被广泛阅读和分享过的。
本文用到的代码可以在这里找到:https://github.com/susanli2016/NLP-with-Python/blob/master/fake_news_COVID.ipynb。


全栈软件工程师必读
尽管经济形势不明朗,仍有很多科技公司在招聘,技术人员可以通过成为全栈软件工程师来增加市场竞争力。这些技术人员负责从前端到后端的整个开发过程,该工作还包括数据结构的完成、架构设计和代码审查。
