

作为一名数据科学家,我们对自己的工作感到无比的自豪。我们可以通过日志、测试编写良好的模块化代码,确保代码按正常运行。
但不幸的是,无论我们在设计上花费多少心思,都不可能得到完美的数据提取(Extraction)、转换(Transformation)和加载( Loading)管道。
事实上,好的代码有时也无法正常运行。即使我们观察得非常仔细,也无法察觉一些因素,必须花费大量的时间和精力,才能知道哪里有问题。
但是,如果我告诉你,有一种方法可以帮你知道哪部分有问题,可以避免出错。有一种工具,在编码运行良好时是不可见的,但在编程运行错误时会自动出现?如果我说这样的工具是存在的,可以帮助你确保代码运行成功。你会怎么看?
欢迎来到Perfect的世界。
Prefect 可帮助你熟练地且透明化地处理工作流管理。Prefect包含各种功能,可以让你的代码具备运行成功或运行失败所需的所有条件。
本文将讨论学习如何使用 Prefect ,以及构建简单 ETL 管道的一些基本概念。
让我们开始吧
安装 Prefect ,并了解一些简单的定义
通过Pip即可安装Prefect :
pip install prefect # please do it inside a virtual environment安装过程还需要 requests 和 pandas 库。操作如下:
pip install requests pandas # also inside a virtual environment从 Prefect 文档中可以看出:
任务(Tasks)本质上是:
- Perfect任务是有关何时运行有特殊规则的函数:这些函数选择性接受输入,执行操作,并可以选择返回输出。
所以任务的目的是执行操作,或执行部分操作。
在 Prefect 中,工作流被定义为“流”(Flows)
- 工作流(或“流”)是任务的容器。流表示任务之间的依赖结构,但不执行任何逻辑。
因此,使用“流”(Flows),你可以将一些任务(Tasks)组合在一起,执行一组特定的所需功能,这更像是一个任务管道。
好的,现在我们以及基本了解了这些内容,接下来让我们看看如何创建任务。
创建任务
这个教程的目标很简单,目的是在 Random user Free API 的帮助下,获取用户列表,并在工作流运行时将列表保存至新的csv文件中。
听起来简单吧?
那么,我们来看看需要构建哪些组件。
首先,将数据导入库,不需要很多数据:
import requests
import pandas as pd
from prefect import task, Flow
import json首先,我们将工作流划分为三个任务(功能):
- 提取(Extract)
从该函数的 API 中获取一定数量的用户。
使用 requests get 函数获取随机用户列表。
@task
def extract(url_from):
response = requests.get(url_from)
if response:
return json.loads(response.content)["results"]
else:
print("No response gotten.") 注意到上面的@task了吗?这就是将函数变成任务所需的全部内容。
下面是用于将用户 json 转换为数据帧的函数。
- 转换(Transform)
转换(Transform)就是将用户的 JSON 字段转换为包含个人字典的people_ list,其中包含每个人的数据。
我们将从所有people的回答中提取三个特征:
- 1. 姓名 = 名字 + 姓氏
- 2. 性别
- 3. 国籍
@task
def transform(data_dict):
people_list = []
for person in data_dict:
single_item = {
'gender': person["gender"],
"name": person["name"]["title"] + person["name"]["first"] + person["name"]["last"],
"nat": "AU",
}
people_list.append(single_item)
# return dataframe from list of dicts
return pd.DataFrame(people_list)最后,我们会用到Load 函数。
- 加载(Load)
此函数的任务非常简单——将 csv 保存至本地目录。
我们指定“data_df”,即我们在转换步骤中构建的数据帧,以及提供我们保存 csv 的文件名,作为此函数的参数。
@task
def load(data_df, filename):
data_df.to_csv(f"{filename}.csv", index=False)下一步,从中构建一个完整的工作流程。
构建工作流程
现在,我们已经定义了可以单独执行任务的函数。现在,我们想将这些函数放在一起,并且建立一个管道,即ETL 管道。
我们用 Flow 执行此操作。
def start_data_collection(num_people_to_fetch):
with Flow("Random User API ETL:") as flow:
# get specific number of people profiles upon each request
people = extract(f'https://randomuser.me/api/?inc=gender,name,nat&results={num_people_to_fetch}')
# make a dataframe out of the response
user_df = transform(people)
# save the dataframe formed to disk
load(user_df, f'{num_people_to_fetch}_people')
return flow具体步骤如下:
- 创建新的Flow 对象,并命名。
- 通过提取方法启动管道,获取用户。
- 将这些用户转化为 Pandas数据框(DataFrame)
- 最后,我们将数据框(DataFrame)保存为csv 文件,并以指定文件名作为参数
完成以上操作后,返回至 Flow 对象。
与按顺序调用函数不同,这一步非常简单——在Flow 对象内部执行相同操作。
测试ETL 工作流程
最后一步,是测试我们构建的内容。通过简单的主函数运行流对象:
if __name__ == "__main__":
flow = start_data_collection(3)
flow.run()到这里就是全部过程。
下列是在命令栏中执行此操作的输出结果:
python main.py
显示管道运行成功的终端输出

这是保存到磁盘上的 csv文件:
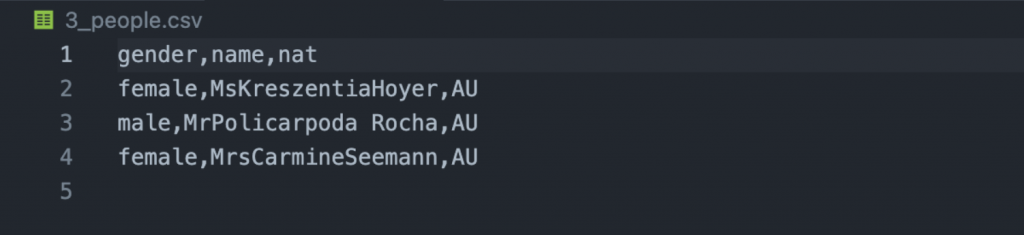
总结
这是一个简单的 ETL 工作流程,可以帮助你开始使用 Prefect。你可以自己按以上步骤执行此操作,同时帮助你理解其他概念,例如 – 故障检测、重试支持等。
我希望这篇文章容易理解,且对你有所帮助。关注我们,一起学习。:)
原文作者:Yash Prakash
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/the-nice-way-to-manage-your-data-science-workflow-7fb92a2ee4a2

【2021职业倦怠】的信号
过去一年,与各行各业很多的专业人士一样,技术人员一直在努力寻找如何在远程工作的同时保持工作与生活间的最佳平衡。工作与生活平衡方面的压力可能至少有一部分归因于COVID-19疫情。

