

Microsoft 的数据分析师职位主要设计并构建数据模型,为公司团队提供有意义的数据和模型。下面是一个真实场景,你可以在 Microsoft 的面试中遇到这种情况。

我们将向你展示如何分解遇到的问题,逐步了解解决问题的逻辑,并讨论如何优化解决方案,提高性能。
微软数据科学家SQL面试中的概念问题
Microsoft 数据科学家面试问题中测试的主要概念包括:
- 聚合函数 – Sum/Count/Group By
- 连接 – joins
- 限制 – limit
微软数据科学家 SQL 面试题
员工项目预算
根据分配给项目中每位员工的预算金额,找出前五个成本最高的项目。排除员工人数为 0 的项目。假设每个员工只参与一个项目。输出结果应该是分配给每个员工的项目名称和预算(即预算与员工的比率)。首先显示预算与员工比率最高的 5 个项目。

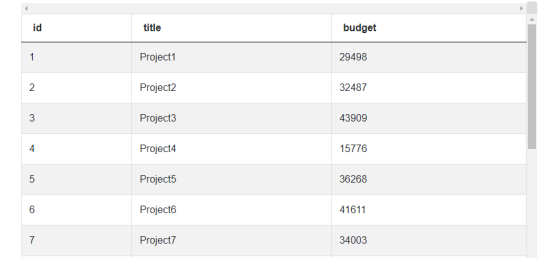
数据集

假设
从上述问题中获取线索,做出以下初步假设:
- 1. 一个项目可以有多个员工,但每个员工只能参与一个项目
- 2. 只需要显示前 5 个结果,因此我们需要按投入成本对结果进行排序,然后限制为 5 个成本最高的项目
该数据集有以下分类:
- id — 每个项目的个人 id
- title — 项目名称
- budget——每个项目的总成本
- emp_id — 员工 id 的整数值
- project_id — 每个项目的唯一 id,与 ms_projects 表中的 id 值相同
在查看 ms_projects 中的budget列时,可以看到,我们处理的是整数,因此我们也假设处理的是整数除法。
方法
SELECT 语句需要返回项目的标题(这样更容易识别)以及项目中每个员工的预算。select的开头很简单:
SELECT title AS project,但是现在,我们必须决定如何返回每个员工的项目成本。对于这种方法,我们将使用整数除法。首先,我们将测试“每个项目可能有多个员工”这一理论。为了测试这一点,我们使用 COUNT() 函数。将其放入一个快速查询中(此处的join会在下面进一步解释),结果表明该假设是正确的:
SELECT title AS project, COUNT(emp_id) AS emps_per_project
FROM ms_projects p
INNER JOIN ms_emp_projects e
ON p.id = e.project_id
GROUP BY 1, budget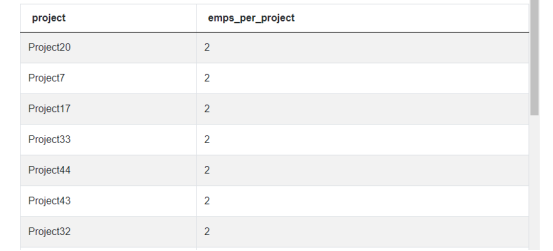
要计算每个项目的员工成本,我们将 ms_projects 中的预算列除以每个项目的员工总数。我们通过使用 COUNT(emp_id) 完成该操作:
SELECT title AS project, budget/COUNT(emp_id) AS budget_emp_ratio
为了收集 SELECT 语句所需的所有列,我们必须将ms_projects 和 ms_emp_projects 表连接在一起。
与上面的解决方案非常相似,为了得到所需的结果,必须在查询中使用 JOIN 语句。这里,我们将在 ms_projects 和 ms_emp_projects 中使用 INNER JOIN语句,其中 ms_emp_projects 中的 project_id 列等同于 ms_projects 上的 id 列:
SELECT title AS project, budget/COUNT(emp_id) AS budget_emp_ratio
FROM ms_projects p
INNER JOIN ms_emp_projects e
ON p.id = e.project_id由于 COUNT() 是一个聚合函数,该函数必须与项目名称以及预算中的 GROUP BY 子句一起使用。
SELECT title AS project, budget/COUNT(emp_id) AS budget_emp_ratio
FROM ms_projects p
INNER JOIN ms_emp_projects e
ON p.id = e.project_id
GROUP BY 1, budget这个查询结果如下:
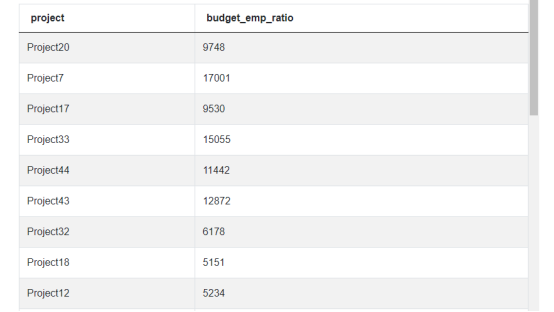
最后,由于 Microsoft 数据科学家面试问题是询问前 5 个成本最高的项目,因此我们按降序对这些项目进行排序,并添加一个 LIMIT 子句,因此结果集中只返回前 5 行。
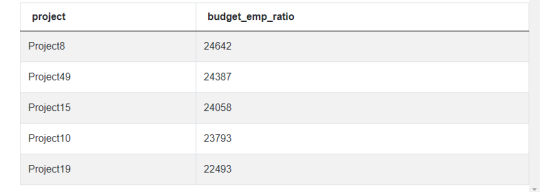
SELECT title AS project, budget/COUNT(emp_id) AS budget_emp_ratio
FROM ms_projects p
INNER JOIN ms_emp_projects e
ON p.id = e.project_id
GROUP BY 1, budget
ORDER BY 2 DESC
LIMIT 5结果如下:
优化
通常情况下,面试官会询问候选人是否可以优化某解决方案。如果不可以,如何制定最佳解决方案?这里的查询已经优化过了,所以我们会讨论为什么无法进一步优化:
- 1. 解决方案符合预期
- 2. 使用了连接方法
- 3. 限制了返回的结果
这里,我们的解决方案提供了满足大致要求的结果:不多也不少。在优化过程中应该问的第一个问题是:当前的解决方案是否可以如预期所示,产生准确的结果。
同时,这里使用的连接方法是 INNER JOIN。INNER JOIN可以检查连接的两个表,只返回右表满足左表连接条件的行。这将排除不必要的数据,同时处理空的数据,因此不需要在稍后的查询中考虑这些数据。如果在这种情况下使用了 LEFT JOIN,那么优化建议则是:将连接方法更改为 INNER。为什么?LEFT JOIN实际上执行两个连接:首先完成内连接;然后,对左侧表中右侧没有匹配项的其余行,将向含左侧行数据的结果集中添加一行,并在右侧插入 NULL 值。这不仅会增加查询时间,而且要求我们必须在查询本身中考虑空值。所以,在本示例中, INNER JOIN 是正确的方法。
最后,限制查询返回的结果不仅满足赋值的参数,还节省了处理时间。需要注意,只有首先用 ORDER BY 子句对结果进行排序,才能优化对结果的限制。这是因为,如果不首先对结果进行排序,内置的 postgreSQL 查询优化器在生成其查询计划时就不会对排序进行约束,也就意味着你的查询将产生无序、不可预测的结果。
结论
现在,你已经了解了如何将常见的 SQL 面试问题分解为基本概念、解决方案所用的逻辑,以及优化结果用到的技术。我们把重点放在了数据科学家或分析师日常使用的 JOINS 和聚合函数。你还了解了如何使用 COUNT 和 ORDER BY 来处理数据。在很多情况下,你会看到多个表,而且需要从中提取和处理数据,因此你必须熟悉 JOINS 及其它技术。如果你喜欢这篇文章,欢迎也查看我们之前的数据科学面试相关文章,他们可以帮助你为面试中经常出现的一些概念做好准备。
原文作者:Nathan Rosidi
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/microsoft-data-scientist-sql-interview-questions-172baceb5fce


