■ 介绍
我一直在热切地进行研究,与朋友交谈并测试一些新的想法。
这些想法将有助于使我成为一个更不可或缺的数据科学家——当然,如果不与那些帮助我取得进展的人分享目前的情况,我是不可能在我的职业生涯中取得进步的。
根据我最近在LinkedIn个人资料上进行的一项民意调查,我惊讶地发现,很多人认为数据科学家必须了解编程标准并遵循工程最佳实践。
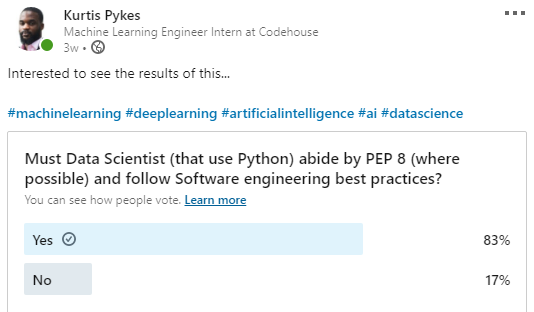
统计学家常常对许多数据科学家(包括我自己)缺乏基本统计学知识感到失望。数学家们认为,在应用程序之前,必须对应用于各种情况的原理有一个深刻的理解,我承认没有。软件工程师希望数据科学家在遵循基本编程原则的同时进行他们的实验。
最让我感到不安的是,每一位投赞成票的人目前都是数据科学家,其中许多人(在投票时)都在担任主要角色——包括像4x Kaggle大师Abhishek Thakur这样的人。你想要的角色决定了你对统计学和其他数学概念(如概率、线性代数和微积分)的理解有多深——尽管基础是绝对必要的——但是软件工程的实践呢?
我曾经是数据科学家中的一员,他们认为我们只是数据科学家,而不是软件工程师,因此我们的责任是从数据中提取有价值的见解,这也是一个事实,然而这项民意调查打乱了我的思维模式,使我陷入了深深的思考之中…
为什么我必须知道软件工程的基础知识,而工作头衔却是数据科学家?
我记得当时的目标——成为一名不可或缺的数据科学家。如果我不知道也不学习软件工程的基础知识,我就不是不可缺少的吗?嗯…是的。基本上如果你是一个数据科学家,编写的代码很可能会投入生产。
在这一点上,我列出了软件工程基本原则的清单,这些原则应该适用于数据科学家。由于没有软件工程的背景,我咨询了许多软件工程师朋友帮我列出清单,并教我如何编写更好的产品代码。
以下是数据科学家应该知道的一些基本知识点。
■ 干净的代码
我想在开始的时候向R用户道歉,因为我没有对用R编码做太多的研究,因此许多干净的代码提示主要是Python用户。
我学的第一门编程语言是Python,因为我能说一口流利的英语,对我来说,Python与英语非常相似。从技术上讲,这指的是Python编程语言的高可读性,这是Python的设计人员在认识到代码读取的频率比编写的频率高之后,特意实现的。
当一个经验丰富的Python开发人员(Pythonista)称部分代码不是“可Python化的”时,通常意味着这些代码行没有遵循通用的指导原则,并且没有以一种被认为是最好的(听起来:最易读的)方式表达其意图。
——《The Hitchhikers Guide to Python》
我将列出构成干净代码的几个因素,但这里不做详细说明,因为我相信有很多很棒的资源比我能更好地涵盖这些主题,比如PEP8和Python中的干净代码:
- 有意义且可发音的命名约定
- 清晰胜过连贯
- 可搜索的名称
- 使你的代码易于阅读
记住,不仅别人会读你的代码,你自己也会。如果你都记不住某件事的意思,那么想象一下别人会怎样。
■ 模块化
这可以部分归咎于我们学习数据科学的方式。如果一个数据科学家不去打开Jupyter笔记本开始做一些探索,我会感到惊讶的。这就是Jupyter笔记本的全部功能:实验!不幸的是,许多关于学习数据科学的课程并没有很好地将我们从Jupyter笔记本转换到脚本——而对于生产环境来说脚本更有效。
当我们谈到模块化代码时,我们指的是分割成独立模块的代码。如果能有效地执行,模块化将允许对可重用的代码进行打包、测试和维护。
其他有助于编写好的模块化代码的因素有:
Don ‘t Repeat Yourself (DRY)——软件开发的一个原则,旨在减少软件模式的重复,用抽象来替代它,或者使用数据规范化来避免冗余。
——来源:维基百科
单一责任原则(SRP)是一种计算机编程原则,它规定计算机程序中的每个模块、类或函数都应该对该程序功能的单个部分负责,这些部分应该被封装起来。
——来源:维基百科
开闭原则——在面向对象的编程中,开闭原则规定“软件实体(类、模块、函数等)应该是开放的,可以扩展的,但是可以修改的”;也就是说,这样的实体可以在不修改源代码的情况下扩展其行为。
——来源:维基百科
■ 重构
代码重构可以定义为在运行时不改变代码的外部行为而重构现有代码的过程。

重构旨在改进软件的设计、结构和/或实现(其非功能属性),同时保留其功能。
——维基百科
重构代码有很多好处,例如,提高代码的可读性和降低复杂性,这反过来会使源代码更容易维护,并且我们配备了一个内部架构来改进我们编写的代码的可扩展性。
此外,我们不能只谈论代码重构而不谈论提高性能。我们的目标是编写一个执行速度更快、使用更少内存的程序,尤其是我们有一个最终用户将要执行某些任务。
■ 测试
注:我在udemy课程的机器学习模型部署中简单地学习了测试(以及这篇文章中涉及的大部分其他想法)。
数据科学是一个有趣的领域,在某种意义上,即使我们的代码中有错误,我们的代码仍然可以运行,而在软件相关的项目中,代码会抛出错误。结果,我们将以误导性的见解而告终(而且可能没有工作)。因此,测试是很有必要的,如果你知道如何去做,你的身价就会上涨。
以下是我们运行测试的一些原因:
- 确保我们得到正确的输出
- 更容易更新代码
- 防止将破坏的代码推入生产环境
我相信还有更多原因,但现在我就讲到这里。
■ 代码检查
代码检查是通过促进最佳编程实践来提高代码质量的,这些实践将允许代码为生产做好准备。此外,这对每个人都有好处,因为它往往会对团队和公司文化有积极的影响。
代码检查的主要目的是捕捉错误,检查对于提高可读性和确保编码标准得到满足也非常有用。
原文作者:Kurtis Pykes
翻译作者:过儿
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/data-scientist-should-know-software-engineering-best-practices-f964ec44cada