

管理Riskified的数据科学部门需要进行大量的招聘——在不到一年半的时间里,我们的工作量翻了一番。作为多个职位的招聘经理,我看过很多简历。
招聘人员筛选一份简历的平均时间是7.4秒,在招聘了几年之后,我的平均时间已经相当快了,但也没有那么极端。
在这篇博文中,我将向大家介绍一些我自己筛选简历的“小窍门”。虽然我不能保证其他人也会使用同样的方法,不同的岗位在每个点的侧重性上也会有所不同,但注意这些点可以帮你通过简历筛选阶段。其中有些方法可能看起来不公平,因为有可能会忽略掉一些合格的求职者。我觉得那些有才华的机器学习求职者如果不在简历上花功夫,可能会通不过这个筛选,但考虑到时间问题,这是最好的折衷办法。一个非常抢手的职位可能会吸引到一百多份简历,如果想要高效的工作效率,筛选简历必须快速。
以下是快速筛选数据科学简历的7个要素:
01 有数据科学家的经验
我将快速浏览一下你的简历,看看你以前的职位,看看哪些被标记为“数据科学家”。还会看一些相关的术语(取决于招聘的职位),如“机器学习工程师”,“研究科学家”或“算法工程师”。我不把“数据分析师”包括在这个范畴内,因为日常工作通常与数据科学家不同,数据分析师这个头衔是一个非常宽泛的术语。
如果你目前在从事数据科学方面的工作,并且有一些其他创造性的工作经历,那么将你的头衔改为数据科学家可能是对你最有利的,这对于事实上是数据科学家的数据分析师来说是非常正确的做法。即使简历中有你所从事项目的描述(包括机器学习),数据科学家以外的头衔也会增加不必要的歧义。
此外,如果你参加过数据科学训练营或者你是该领域的硕士,这可能会被认为是你数据科学经验的开始(除非你之前做过类似的工作)。
02 面向业务的成就
理想情况下,我想看到你做过什么(技术方面)和业务结果是什么。缺乏精通技术的数据科学家,可以用商业术语进行交流。如果你能分享你的工作所影响的商业关键绩效指标,那在我的记录中会是一个很大的加分项。例如,表明你的模型在AUC上的改进是可以的,但解决由于你的模型改进而导致的转化率提高意味着你已经“get it”——业务影响是最终真正重要的东西。比较以下描述同一工作的不同重点的备选方案(技术与业务):
- a.银行贷款违约率模型——改进模型的Precision-Recall AUC从0.94到0.96。
- b.银行贷款违约率模型——业务部门年营收增加3% (每年50万美元),同时保持不变的违约率。
03 教育背景
你受过什么教育,在什么领域?是知名机构吗?对于最近毕业的学生,我也会看他们的GPA,以及他们是否获得过任何优秀奖项或荣誉,比如进入了校长或院长优秀学生名单。由于数据科学是一个非常开放的领域,没有任何标准化的测试,也没有必要的知识,人们可以通过各种方法进入这个领域。如果你没有任何数据科学方面的正规教育,也没关系,但你需要证明你在该领域的工作记录和/或在类似领域的高级学位。
04 布局/视觉吸引力
我看过一些漂亮的简历(我保存了一些以备个人灵感之用),但我也收到了一些没有任何格式的文本文件(.txt)。写简历是件痛苦的事,如果你选择了数据科学,那么你很有可能不喜欢在业余时间创造美学设计。你需要寻找一个好的模板,使你能够在有限的空间内完成所有的事情。合理使用空间——这很有用,可以分割页面并突出那些不属于按时间顺序排列的工作/教育经历的特定部,这可能包括你熟悉的技术堆栈,从自我项目列表到你的github或博客和其他的链接,一些简单的图标也可以突出部分标题。
许多应聘者在他们熟悉的每种语言/工具旁边使用1-5颗星或条形图。就我个人而言是不太喜欢这种方法的,原因如下:
- 这是非常主观的——你的“5星”和别人的“2星”能一样吗?
- 他们把语言和工具混在一起,最糟糕的情况是把软技能混在一起——说你在领导方面的“4.5星”并没有什么帮助。
我也看到过这种方法被滥用的情况,即采用主观的度量方法并将其转化为饼图(30%的python,10%的团队合作,等等)。虽然这也算是一种脱颖而出的创造性方法,但它显示出对不同图表概念背后缺乏基本理解。
下面是两个我觉得很吸引人的简历例子,为了保护隐私,细节都被模糊了。
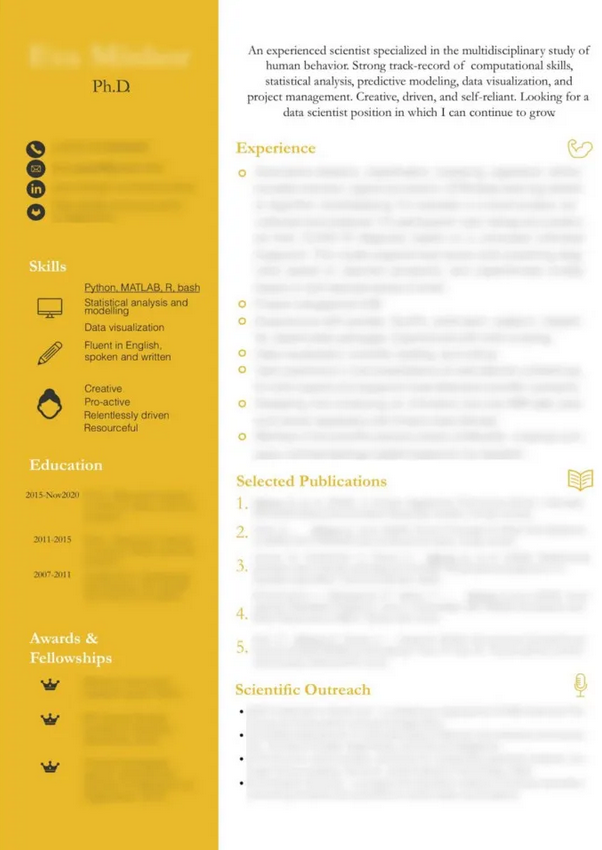
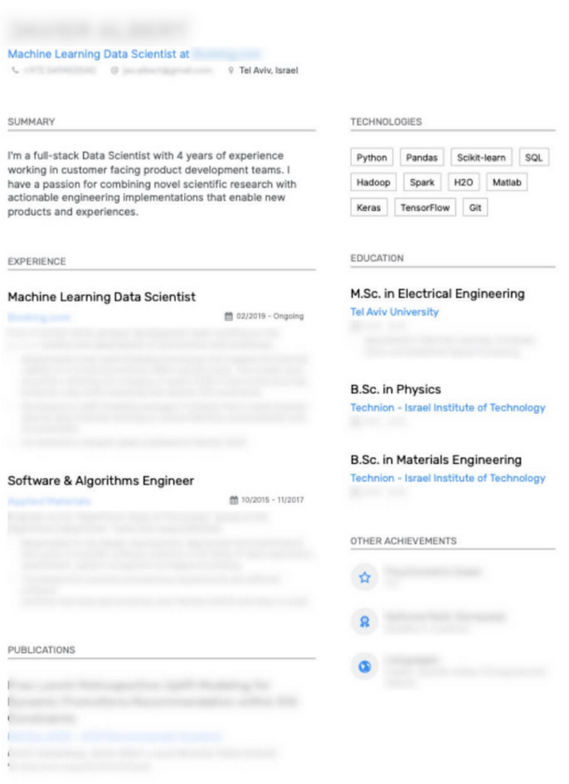
注意这两个例子中使用垂直分割来区分经验、技能、成就和出版物。在这两种情况下,简短的总结段落有助于描述他们的背景。(经所有者许可使用)
05 机器学习的多样性
我需要两种类型的产品:
- 算法类型-结构化/经典ML与深度学习。一些求职者只使用了深度学习,包括结构化数据,这些数据本可以更好地应用于基于树的模型。虽然作为DL专家本身没有问题,但限制工具集会限制解决方案。正如马斯洛所说:“如果你拥有的唯一工具是一把锤子,你就会把每个问题都看作钉子。”“在riskfied,我们处理结构化的、领域驱动的、特征工程的数据,这些数据最好用于各种形式的提升树,让一个简历都指向DL的人是有问题的。
- ML领域——这通常与计算机视觉和自然语言处理这两个需要很多专业知识的领域相关。这些领域的专家是很需要的,而且在很多情况下,他们的整个职业生涯都将专注于这些领域。如果你正在寻找从事该领域工作的人,这一点很关键,但通常不适合从事一般的数据科学工作的人。所以,如果你的大部分经验都是在NLP,而你正在申请一个领域之外的职位,试着强调我们的职位/项目你已经在结构化数据方面工作过,以展示多样性。
06 技术堆栈
这通常可以被分解成语言、特定的包 (scikit learn、pandas、dplyr等)、云及其服务 (AWS、Azure、GCP) 或其他工具。有些求职者会将其与他们熟悉的算法或架构 (RNN、XGBoost、K-NN) 混在一起。就我个人而言,我更倾向于围绕技术和工具展开;当提到一个具体的算法时,我想知道求职者的ML理论知识是否仅仅局限于这些具体的算法。
在这里,我在寻找技术堆栈的相关性——它们是过去几年的(这是求职者动手学习新技能的积极迹象)、堆栈的广度(它们是否非常局限于特定的工具,或者它们熟悉很多东西)以及与我们的堆栈的契合度(我们需要教多少)。
07 项目经验
你有没有做过什么可以在GitHub上分享的东西?任何Kaggle竞争或课外做的项目都非常有帮助,可以查看简洁的代码、预处理类型、特征工程、EDA、算法选择和现实项目中需要解决的无数其他问题。在你的GitHub和Kaggle账户上添加一个链接,以便面试官深入了解你的代码。
如果你没有太多的经验,你很有可能会被问及一个或多个这样的项目。在我进行的一些面试中,应聘者对项目的印象不太好,我们也无法就他们所做的选择及其背后的原因展开对话。一定要温习你之前的工作,否则不要把它写在简历上。同样,确保你展示了你最好的作品,并且你已经投入了足够的时间和精力。2-3个高质量的项目比8-10个中等 (或较低) 质量的项目要好。
总结 summary
如果你正在寻找一个新的数据科学职位,可以花点时间阅读一下这篇文章。如果你不能把所有这些要点都标记出来,那就标记得越多越好,希望这些建议能够帮你从人群中脱颖而出,在简历筛选中取得优异成绩。
祝你好运,求职愉快!
在筛选数据科学简历时,你有不同的方法吗?请在下面的评论区分享出来~
原文作者:Elad Cohen
翻译作者:过儿
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/7-must-haves-in-your-data-science-cv-9316841aeb78

硅谷大厂薪资一览:Facebook, Twitter, Snap, Pinterest
社交媒体界正在经历一场巨变,从言论自由到广告定位算法,各个平台都面临着压力。如果你是他们的技术人员,就项目的社会影响而言,你可能需要做出一些艰难的决定。

