

SQL是用于数据分析和数据处理的最重要的编程语言之一,因此考察关于SQL的题目始终是数据科学相关工作(如数据分析师,数据科学家和数据工程师)的面试过程中最重要的一部分。
SQL相关的面试的目的是评估候选人的技术能力和解决问题的能力。因此,重要的不仅仅是要根据样本数据编写出正确的query,还要像对待真实数据库一样考虑到各种情况和极端案例。
我曾协助设计和参与了针对数据科学候选人的SQL面试问题,并为许多大型技术型公司和我自己的创业公司进行过许多SQL面试。在这篇文章中,我将解释SQL面试问题中常见的模式,并提供如何在SQL Query中巧妙处理它们的方法。
提出问题
想要成功完成SQL面试,最重要的是要通过询问尽可能多的问题,来获得有关任务和数据样本的所有详细信息。理解最终需求可以节省你以后重复问题的时间,并使你能够很好地处理极端案例。
许多候选人往往在不了解SQL问题或数据集的情况下,就直接开始寻找解决方案。后来在我指出了他们答案中的问题之后,他们又不得不反复修改他们的queries。最后,他们在重复中浪费了很多面试时间,甚至可能最后都没有找到正确的解决方案。
我建议把SQL面试视作你正在与一个业务合作伙伴一起工作。在提供解决方案之前,你需要收集到所有对数据请求的相关要求。
查找到薪水最高的前3名员工。
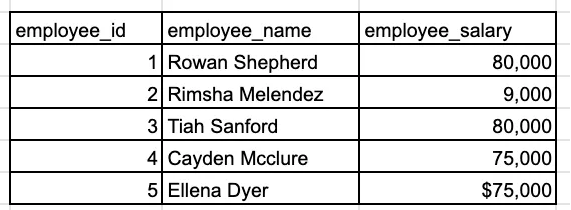
你应该要求面试官解释“前三名”的具体意思。我应该在结果中只包括那3名员工吗?你想要我如何处理薪资出现相同的情况?此外,仔细查看样本员工数据, 薪水列的数据类型是什么?在计算之前,我是否需要清理数据?
哪种Join
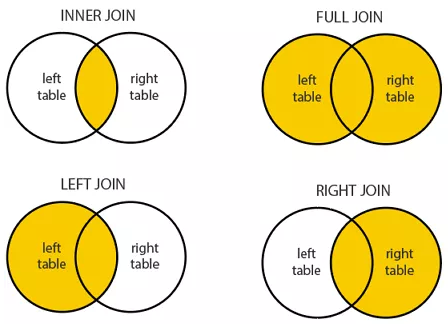
在SQL中,JOIN通常用于合并来自多个表里的信息。有四种不同类型的JOIN,但是在大多数情况下,我们只会使用INNER,LEFT和FULL JOIN,因为RIGHT JOIN不是很直观,而且可以使用LEFT JOIN代替写出。在SQL面试中,你需要根据指定问题的特定要求来选择要使用的JOIN。
找到每个学生参加的课程总数。(显示学生id,姓名和上课的数量。)

你可能已经注意到,并不是所有出现在class_history表中的学生都出现在了student表中,可能是因为这些学生已不是在册学生。(这实际上是在事务型数据库中非常典型的案例,因为记录通常会在不活跃时被删除。)根据面试官是否希望结果中出现不活跃的学生,我们需要使用LEFT JOIN或INNER JOIN来组合两个表:
WITH class_count AS (
SELECT student_id, COUNT(*) AS num_of_class
FROM class_history
GROUP BY student_id
)
SELECT
c.student_id,
s.student_name,
c.num_of_class
FROM class_count c
-- CASE 1: include only active students
JOIN student s ON c.student_id = s.student_id-- CASE 2: include all students
-- LEFT JOIN student s ON c.student_id = s.student_idGroup By
GROUP BY是SQL中最重要的功能,因为它广泛用于各种数据聚合。如果在SQL问题中看到例如求和,平均值,最小值或最大值之类的关键字,则表明你可能会在query中使用到GROUP BY。一个常见的错误是在过滤数据和使用GROUP BY时,混淆了WHERE和HAVING的用法 — 我已经看到很多人犯了这个错误。
计算每个学生在每个学年的平均要求GPA,并找到每个学期符合Dean’s List(GPA≥3.5)资格的学生。
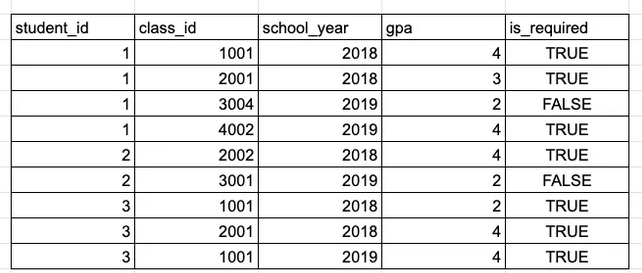
由于我们在GPA计算中只考虑必修课程,因此需要使用WHERE is_required = TRUE来排除选修课程。我们需要每位学生每年的平均GPA,因此我们要GROUP BY student_id列和school_year列,并取gpa列的平均值。最后,我们仅保留平均GPA高于3.5的学生行,这里可以使用HAVING来实现。让我们将所有内容放在一起:
SELECT
student_id,
school_year,
AVG(gpa) AS avg_gpa
FROM gpa_history
WHERE is_required = TRUE
GROUP BY student_id, school_year
HAVING AVG(gpa) >= 3.5请记住,每当在query中使用GROUP BY时,你就只能选择Group By列和聚合列,因为其他列中的行级信息已被舍弃了。
有些人可能想知道WHERE和HAVING之间有什么区别,或者为什么我们不直接写HAVING avg_gpa> = 3.5而是写了一堆指定函数。我将在下一节中详细解释。
SQL Query的执行顺序
大多数人都从SELECT开始,从上到下编写SQL Query,但是你知道SELECT是SQL引擎执行的最后一个函数之一吗?以下是SQL Query的执行顺序:
- FROM, JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT, OFFSET
再看看前面的那个例子。因为我们想在计算平均GPA之前过滤掉选修课程,所以我使用WHERE is_required = TRUE而不是HAVING,因为WHERE会在GROUP BY和HAVING之前执行。我不能写HAVING avg_gpa >= 3.5的原因是,avg_gpa被放在了SELECT的那一部分,因此无法在SELECT前执行的步骤中使用它。
我建议在编写Query时遵循执行顺序,这在你编写复杂query时会很有帮助。
Window函数
Window函数也经常出现在SQL面试中。一共有五种常见的Window函数:
- RANK / DENSE_RANK / ROW_NUMBER:这些是通过排序某些特定的列,为每一行分配一个等级。如果给出了一个用来分区 的列,那么行就会在其所属的组中排列。
- LAG / LEAD:它根据指定的顺序和组,从前一行或后一行检索该列的值。
在SQL面试中,重要的是要了解rank函数之间的差异,并知道在什么时候使用LAG / LEAD。
查找每个部门中薪水最高的前3名员工。
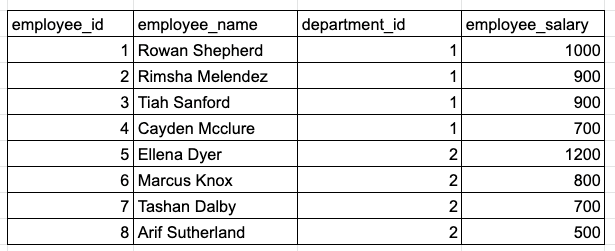
当一个SQL问题要求找到“ TOP N”时,我们可以使用ORDER BY或rank函数来回答该问题。但是,在此示例中,它要求计算“每个Y中的TOP N X”,这强烈提示了我们应该使用rank函数,因为我们需要对每个分区组中的行进行排列。
以下query中,在无视薪水相同的情况下,找到了3个薪水最高的员工:
WITH T AS (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY employee_salary DESC) AS rank_in_dep
FROM employee_salary)
SELECT * FROM T
WHERE rank_in_dep <= 3--注意:使用ROW_NUMBER时,每行将具有唯一的等级编号,记录出现相同时,等级会是随机分配的。例如,Rimsha和Tiah在不同的query运行中可能排名2或3。
此外,根据如何处理薪资相同时的情况,我们也可以选择其他rank函数。同样,细节很重要!
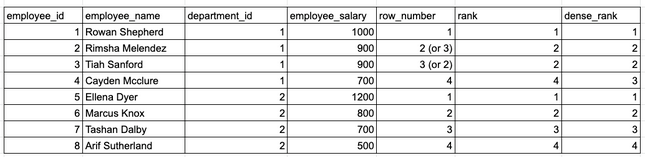
在使用ROW_NUMBER,RANK和DENSE_RANK函数的不同结果的比较。
重复项
SQL面试中的另一个常见陷阱是忽略重复数据。尽管样本数据中的某些列似乎有不同的值,但面试官还是希望候选人考虑到所有可能性,就像他们在处理真实数据一样。例如,在上一个示例的employee_salary表中,有的员工可能有相同的名字。
避免重复造成潜在问题的一种简单方法是,始终使用ID列来找到不同的记录。
使用employee_salary表查找每个员工在所有部门的总薪水。
正确的解决方案是GROUP BY employee_id,然后使用SUM(employee_salary)来计算总工资。如果需要显示雇员姓名,就在最后与Join员工表以检索员工的姓名信息。
在这里,错误的方法是去GROUP BY employee_name。
NULL
在SQL中,任何位置都可以得出以下三个值之一:true,false和NULL(这是未知或缺失数据值的特有关键字)。处理NULL数据可能会出乎意料的棘手。在SQL面试中,面试官可能会特别观察你的解决方案是否处理了NULL值。有时,很明显有一列是不可为空的(例如ID列),但对于大多数其他列,很可能会出现NULL值。
我建议你确认示例数据中的关键列是否可为空,如果可以,请利用IS(NOT)NULL,IFNULL和COALESCE之类的功能来处理这些极端情况。
交流
最后,但同样重要的是 —在SQL面试期间,保持交流持续进行。
我面试了许多候选人,除开他们有疑问的时候,他们几乎不会开口说话。当然,如果他们最终能提出完美的解决方案,那确实是没问题。但是,在技术面试期间,保持交流是一个好主意。例如,你可以谈论你对问题和数据的理解,计划如何解决问题,为什么使用某些方法,而不是其他替代方,法以及正在考虑哪些极端情况。
总结
- 首先,保持问问题,收集所需的详细信息。
- 仔细选择INNER, LEFT, and FULL JOIN。
- 使用GROUP BY来集合数据,并正确使用WHERE和HAVING。
- 了解三个rank函数之间的差异。
- 知道何时使用LAG / LEAD window函数。
- 如果你在创建复杂的query时遇到困难,尝试遵照SQL执行顺序来写。
- 考虑潜在的数据问题,例如重复值和NULL值。
- 与面试官沟通你的思维过程。
为了帮助你了解如何在实际的SQL面试中使用这些方法,我将在下面的视频中从头到尾逐步介绍一个SQL面试案例问题:https://towardsdatascience.com/crack-sql-interviews-6a5fc90ec763。
希望本文对你准备下一次数据科学面试有所帮助。
原文作者:Xinran Waibel
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/crack-sql-interviews-6a5fc90ec763


